Prognose-Mehrwert
Forecast value added1 (FVA) ist ein einfaches Instrument zur Bewertung der Leistung jedes Schrittes (und Mitwirkenden) im Prozess der Nachfrageprognose. Sein ultimatives Ziel ist es, Verschwendung im Prognoseprozess zu beseitigen, indem die menschlichen Schnittstellen (Anpassungen) entfernt werden, die die Prognosegenauigkeit nicht erhöhen. FVA beruht auf der Annahme, dass eine höhere Prognosegenauigkeit angestrebt werden sollte und dass es wünschenswert ist, jene Anpassungen zu identifizieren, die sie erhöhen, und jene zu eliminieren, die dies nicht tun. Trotz guter Absichten zeigt FVA einen begrenzten Einmaleffekt und, wenn es kontinuierlich eingesetzt wird, eine Vielzahl von Nachteilen, einschließlich fehlerhafter mathematischer Annahmen, Missverständnissen über den intrinsischen Wert einer erhöhten Prognosegenauigkeit und dem Fehlen einer soliden finanziellen Perspektive.

Überblick über den Prognose-Mehrwert
Forecast value added zielt darauf ab, Verschwendung zu beseitigen und die Genauigkeit der Nachfrageprognose zu erhöhen, indem Beiträge aus mehreren Abteilungen (einschließlich solcher, die nicht der Nachfrageplanung angehören, wie Sales, Marketing, Finance, Operations, etc.) gefördert und bewertet werden. Durch die Bewertung des Wertes jeder menschlichen Schnittstelle im Prognoseprozess liefert FVA Unternehmen umsetzbare Daten zu den Anpassungen, die die Prognose verschlechtern, und bietet ihnen so die Möglichkeit, Bemühungen und Ressourcen zu identifizieren und zu eliminieren, die nicht zu einer besseren Prognosegenauigkeit beitragen.
Michael Gilliland, dessen The Business Forecasting Deal der Praxis zu großer Bekanntheit verhalf, argumentiert2
“FVA hilft dabei sicherzustellen, dass alle in den Prognoseprozess investierten Ressourcen – von Computerhardware und -software bis hin zur Zeit und Energie der Analysten und des Managements – die Prognose verbessern. Wenn diese Ressourcen nicht zur Prognose beitragen, können sie bedenkenlos auf wertvollere Aktivitäten umgeleitet werden."
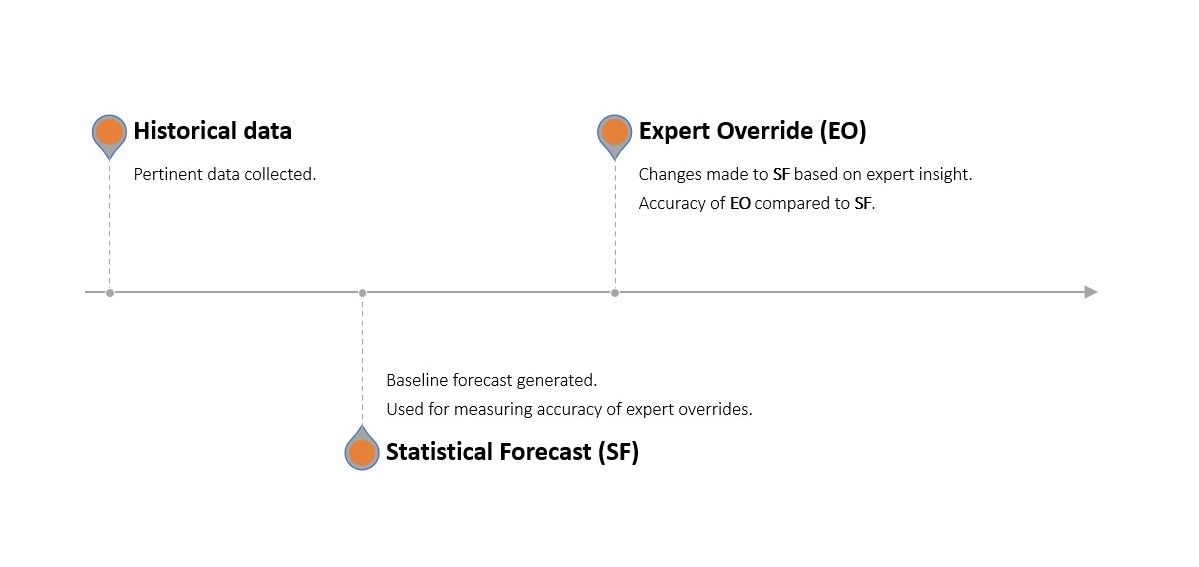
Man identifiziert, welche Aktivitäten und Ressourcen helfen, durch einen mehrstufigen Prognoseprozess, in dem eine statistische Prognose mithilfe der vorhandenen Prognosesoftware des Unternehmens erstellt wird. Diese statistische Prognose wird anschließend von jeder ausgewählten Abteilung manuell angepasst (Overrides). Diese angepasste Prognose wird dann mit einer naiven, Benchmark-Prognose (ohne Änderungen, die als Placebo fungiert) und der tatsächlichen, beobachteten Nachfrage verglichen.
Wenn die von den Abteilungen vorgenommenen Änderungen die statistische Prognose im Vergleich zur unberührten statistischen Prognose genauer machten, trugen sie einen positiven Wert bei. Wenn sie sie weniger genau machten, trugen sie einen negativen Wert bei. Ebenso, wenn die statistische Prognose genauer war als das Placebo, fügte sie einen positiven Wert hinzu (und umgekehrt, wenn sie weniger genau war).
FVA ist somit „[ein Maß für] die Veränderung einer Prognoseleistungsmetrik, die einem bestimmten Schritt oder Teilnehmer im Prognoseprozess zugerechnet werden kann“2.
Befürworter des Forecast Value Added argumentieren, dass es ein wesentliches Instrument im modernen supply chain management ist. Indem sie diejenigen Teile des Prognoseprozesses identifizieren, die vorteilhaft sind, und diejenigen, die es nicht sind, können Organisationen ihre Prognosegenauigkeit optimieren. Die übergeordnete Begründung lautet, dass eine verbesserte Prognose zu einer besseren Bestandsverwaltung, reibungsloseren Produktionsplanung und einer effizienteren Ressourcenzuteilung führt.
Dies sollte folglich die Kosten senken, Fehlbestände minimieren und Überbestände reduzieren, während gleichzeitig die Kundenzufriedenheit steigt und ein inklusiverer Prognose- und Unternehmenskodex entsteht. Der Prozess hat sich als bemerkenswert populär erwiesen, wobei FVA bei mehreren namhaften Unternehmen in außergewöhnlich wettbewerbsintensiven Branchen angewendet wurde, darunter Intel, Yokohama Tire und Nestle3.
Durchführung einer Prognose-Mehrwert-Analyse
Die Durchführung einer Prognose-Mehrwert-Analyse umfasst mehrere intuitive Schritte, die typischerweise in etwa wie folgt aussehen:
-
Definieren Sie den Prozess, indem Sie die einzelnen Schritte oder Komponenten identifizieren, d.h. die Liste der Abteilungen, die konsultiert werden, die Reihenfolge der Konsultation und die spezifischen Parameter, die jeder Mitwirkende zur Anpassung der anfänglichen Prognose verwendet.
-
Erstellen Sie eine Benchmark-Prognose. Diese Benchmark nimmt in der Regel die Form einer naiven Prognose an. Eine statistische Prognose wird ebenfalls erstellt, gemäß dem üblichen Prognoseprozess im Unternehmen unter Verwendung desselben Datensatzes, der zur Erstellung der Benchmark verwendet wurde. Diese statistische Prognose dient als Grundlage für alle folgenden Anpassungen
-
Sammeln Sie Erkenntnisse von den benannten Mitwirkenden, wobei Sie die im ersten Schritt festgelegten genauen Parameter einhalten. Dies könnte Einblicke in Markttrends, Werbepläne, operative Einschränkungen usw. umfassen.
-
Berechnen Sie den FVA für jeden Mitwirkenden, indem Sie die Genauigkeit der statistischen Prognose vor und nach dessen Beitrag vergleichen. Im Gegenzug wird die Genauigkeit der statistischen Prognose mit der der einfachen Benchmark-Prognose kontrastiert. Beiträge, die die Prognosegenauigkeit verbessern, erhalten einen positiven FVA, während diejenigen, die die Genauigkeit verringern, einen negativen FVA erhalten.
-
Optimieren Sie, indem Sie Beiträge mit negativem FVA verbessern oder eliminieren, während Sie diejenigen mit positivem FVA beibehalten oder verstärken.
Diese Schritte bilden einen kontinuierlichen Prozess, der iterativ im Streben nach höherer Prognosegenauigkeit verbessert wird. Der FVA-Prozess und wie er sich von einem traditionellen Prognoseprozess unterscheidet, wird unten veranschaulicht.
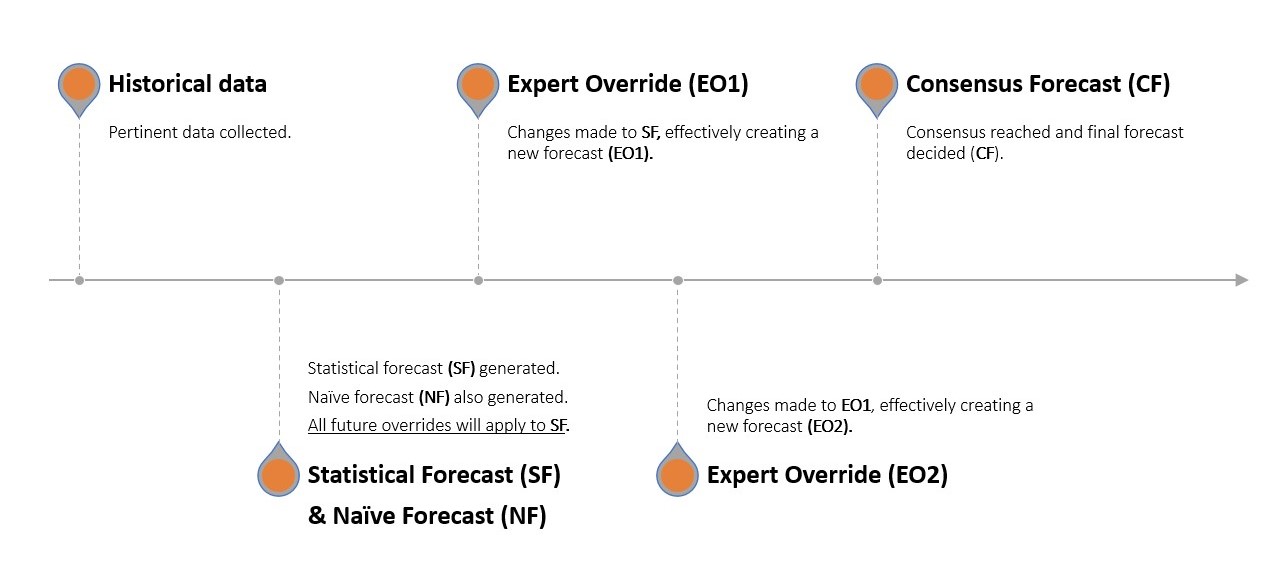
Betrachten wir einen Apfelverkäufer. Paul (Demand Planning) informiert das Management, dass das Unternehmen in jedem der letzten 3 Monate 8 Äpfel verkauft hat. Die naive Prognose sagt, dass das Unternehmen auch im nächsten Monat wieder 8 Äpfel verkaufen wird, aber Paul verfügt über eine fortschrittliche statistische Software, die eine Prognose von 10 verkauften Äpfeln abgibt (statistische Prognose). John (Marketing) meldet sich und erklärt, dass er plant, in diesem Monat einen schlagfertigen neuen Slogan herauszubringen6 und die Verkäufe aufgrund seines scharfsinnigen Witzes wahrscheinlich höher ausfallen werden. George (Sales) beabsichtigt, Äpfel zu Bündelpreisen zusammenzufassen und die Preise leicht zu senken, um die Verkäufe weiter anzukurbeln und die Nachfrage zu steigern. Richard (Operations) ist zunächst ratlos, passt dann aber die prognostizierte Nachfrage an, um eine bevorstehende Ausfallzeit in einer wichtigen Apfelsortiermaschine zu berücksichtigen, von der er annimmt, dass sie sich negativ auf die Fähigkeit des Unternehmens auswirken wird, der Nachfrage gerecht zu werden. Die statistische Prognose wurde somit dreimal manuell angepasst. Die Abteilungen versammeln sich anschließend, um mündlich zu einer Konsensprognose zu gelangen.
Einen Monat später führt das Unternehmen einen Backtest durch, um zu bestätigen, wie groß das Delta7 in jedem Schritt dieser Prognosekette war – d.h., wie stark der Beitrag jeder Abteilung abwich. Dies ist nicht schwierig, da sie nun über die tatsächlichen Verkaufszahlen des Vormonats verfügen, und Paul kann Schritt für Schritt isolieren, wie viel Fehler jeweils durch John, George und Richard sowie durch die Konsensprognosephase8 eingeführt wurde.
Die mathematische Perspektive auf den Prognose-Mehrwert
Im Hintergrund ist Forecast value added ein bemerkenswert einfacher und absichtlich unkomplizierter Prozess. Im Gegensatz zu Prognoseprozessen, die fortgeschrittene mathematische Kenntnisse und statistisches Denken erfordern, ist FVA „ein Ansatz, der auf gesundem Menschenverstand beruht und leicht verständlich ist. Er drückt die Ergebnisse von etwas Tun im Vergleich dazu aus, nichts getan zu haben“3.
Das Ausdrücken der Ergebnisse von etwas Tun versus Nichtstun erfordert jedoch immer noch mathematische Eingriffe, und dies nimmt typischerweise die Form einer einfachen Zeitreihe an – das Rückgrat traditioneller Prognosemethoden. Das primäre Ziel der Zeitreihenanalyse besteht darin, zukünftige Nachfrage bequem und intuitiv als einen einzelnen, umsetzbaren Wert darzustellen. Im Kontext von FVA dient die Baseline-Zeitreihe als Placebo oder Kontrolle, mit der alle Analysten-Overrides (wie im vorherigen Abschnitt detailliert) verglichen werden. Eine Baseline-Zeitreihe kann durch verschiedene Methoden generiert werden, üblicherweise unter Einbeziehung verschiedener Formen naiver Prognosen. Diese werden häufig unter Verwendung von Metriken wie MAPE, MAD und MFE bewertet.
Auswahl einer Benchmark-Prognose
Die Wahl der Baseline-Prognose variiert je nach den Zielen oder Einschränkungen des betreffenden Unternehmens.
-
Naive Prognose und saisonale naive Prognosen werden oft wegen ihrer Einfachheit gewählt. Sie sind leicht zu berechnen und zu verstehen, da sie auf der Annahme beruhen, dass sich frühere Daten in der Zukunft wiederholen. Sie bieten in vielen Kontexten eine sinnvolle Ausgangsbasis, insbesondere wenn die Daten relativ konstant sind oder ein klares Muster (Trend, Saisonalität) aufweisen.
-
Random Walk und saisonaler Random Walk werden typischerweise verwendet, wenn die Daten erhebliche Zufälligkeit oder Variabilität aufweisen oder wenn ein ausgeprägtes saisonales Muster besteht, das ebenfalls zufälligen Schwankungen unterliegt. Diese Modelle fügen dem Konzept der naiven Prognose ein Element der Unvorhersehbarkeit hinzu, um die inhärente Unsicherheit der Prognose zukünftiger Nachfrage widerzuspiegeln.
Bewertung der Ergebnisse des Forecast Value Added
-
MFE (Mean Forecast Error) kann verwendet werden, um zu beurteilen, ob eine Prognose dazu neigt, die tatsächlichen Ergebnisse zu überschätzen oder zu unterschätzen. Dies könnte eine nützliche Metrik in einer Situation sein, in der es teurer ist, zu viel vorherzusagen als zu wenig, oder umgekehrt.
-
MAD (Mean Absolute Deviation) und MAPE (Mean Absolute Percentage Error) bieten Maße der Prognosegenauigkeit, die sowohl Über- als auch Unterschätzungen der Nachfrage berücksichtigen. Sie könnten als Genauigkeitsindikatoren verwendet werden, wenn es wichtig ist, die Gesamtgröße der Prognosefehler zu minimieren, unabhängig davon, ob sie zu Über- oder Unterschätzungen führen.
Obwohl MAPE häufig in FVA-bezogenen Quellen verwendet wird, gibt es unterschiedliche Meinungen darüber, welche Prognosemetrik-Konfiguration in einer FVA-Analyse genutzt werden sollte2 4 9.
Grenzen des FVA
Forecast value added ist trotz seines integrativen Ansatzes, edler Ziele und niedriger Eintrittsbarrieren argumentativ einer umfangreichen Reihe von Einschränkungen und falschen Annahmen unterworfen. Diese Defizite erstrecken sich über eine Vielzahl von Bereichen, einschließlich der Mathematik, moderner Prognosetheorie und der Wirtschaft.
Prognosen sind nicht kollaborativ
Forecast value added basiert auf der Annahme, dass kollaborative Prognosen vorteilhaft sind, insofern als dass mehrere (und sogar konsensbasierte) menschliche Overrides positiven Mehrwert hinzufügen können. FVA glaubt zudem, dass dieser positive Prognosewert im gesamten Unternehmen verteilt ist, da Mitarbeiter verschiedener Abteilungen alle wertvolle Einblicke in die zukünftige Marktnachfrage besitzen können.
Daher sieht FVA das Problem darin, dass dieser kollaborative Ansatz mit lästigen Ineffizienzen einhergeht, da einige menschliche Schnittstellen negativen Mehrwert beitragen. FVA zielt somit darauf ab, die verschwenderischen Prognosemitwirkenden herauszufiltern, um die guten zu identifizieren.
Leider steht die Vorstellung, dass Prognosen als kollaborativer, abteilungsübergreifender Prozess besser sind, im Widerspruch zu dem, was moderne statistische Prognosen zeigen – auch im Einzelhandel.
Eine umfangreiche Überprüfung des fünften Makridakis-Prognosewettbewerbs10 zeigte, dass „alle 50 leistungsstärksten Methoden auf ML (machine learning) basierten. Daher ist M5 der erste M-Wettbewerb, bei dem alle leistungsstarken Methoden sowohl ML-Methoden als auch besser als alle anderen statistischen Benchmarks und deren Kombinationen waren“ (Makridakis et al., 2022)11. Der M5-Genauigkeitswettbewerb basierte auf der Prognose von Verkaufszahlen anhand historischer Daten für das umsatzstärkste Einzelhandelsunternehmen der Welt (Walmart).
Tatsächlich, laut Makridakis et al. (2022), wurde „das siegreiche Modell [im M5] von einem Studenten mit wenig Prognosekenntnissen und wenig Erfahrung im Aufbau von Verkaufsprognosemodellen“11 entwickelt, was Zweifel daran aufkommen lässt, wie wichtig die Markteinsichten unterschiedlicher Abteilungen in einem Prognosekontext wirklich sind.
Dies soll nicht bedeuten, dass komplexere Prognosemodelle per se wünschenswert sind. Vielmehr übertreffen ausgefeilte Modelle oft einfache Modelle, und FVA’s kollaborative Prognose ist ein einfacher Ansatz für ein komplexes Problem.
Ignoriert zukünftige Unsicherheit
FVA geht – wie viele Werkzeuge und Techniken im Bereich der Prognose – davon aus, dass Wissen über die Zukunft (in diesem Fall die Nachfrage) in Form einer Zeitreihe dargestellt werden kann. Es verwendet eine naive Prognose als Maßstab (typischerweise eine Kopie vergangener Verkaufszahlen) und lässt Mitarbeitende die Werte einer statistischen Prognose manuell auf- oder abrunden. Dies ist aus zwei Gründen fehlerhaft.
Zunächst einmal ist die Zukunft – sei es allgemein oder im prognostischen Kontext – unaufhebbar unsicher. Daher ist es von vornherein ein fehlgeleiteter Ansatz, sie als einen einzelnen Wert auszudrücken (selbst wenn dies mit einer Formel zur Berechnung des Sicherheitsbestands ergänzt wird). Angesichts der unaufhebbaren Unsicherheit der Zukunft ist der vernünftigste Ansatz, eine Bandbreite wahrscheinlicher zukünftiger Werte zu bestimmen, bewertet in Bezug auf ihren potenziellen finanziellen Ertrag. Dies übertrumpft – aus der Perspektive des Risikomanagements – den Versuch, einen einzelnen Wert anhand einer traditionellen Zeitreihe zu identifizieren, der das Problem der zukünftigen Unsicherheit völlig ignoriert.
Zweitens sind die Einsichten (so nützlich sie auch erscheinen mögen) der Mitarbeitenden in der Regel nicht leicht (wenn überhaupt) in eine Zeitreihenprognose zu übersetzen. Betrachten Sie eine Situation, in der ein Unternehmen bereits im Voraus weiß, dass ein Konkurrent kurz davorsteht, in den Markt einzutreten. Alternativ stellen Sie sich eine Welt vor, in der wettbewerbsrelevante Erkenntnisse darauf hindeuten, dass der stärkste Wettbewerber plant, eine beeindruckende neue Sommermodekollektion herauszubringen. Die Annahme, dass derartige Einsichten von Laien gemeinschaftlich in einen einzigen Wert, der in einer Zeitreihe ausgedrückt wird, eingearbeitet werden können, ist unrealistisch.
In Wirklichkeit werden jegliche Ähnlichkeiten zu tatsächlichen zukünftigen Verkaufszahlen (positiver Mehrwert) völlig zufällig sein, insofern als menschliche Übersteuerungen (sei es das Auf- oder Abrunden der Nachfrage) gleiche Ausdrucksformen derselben fehlerhaften Eingabe darstellen. Eine Person, die einen negativen Mehrwert beiträgt, liegt aus logischer Sicht somit weder „richtig“ noch „falsch“ im Vergleich zu einer Person, die einen positiven Mehrwert beisteuert.
Im Kern versucht FVA, dreidimensionale Eigenschaften (menschliche Einsichten) auf eine zweidimensionale Fläche (eine Zeitreihe) zu übertragen. Es mag aus einem bestimmten Winkel richtig aussehen, aber das bedeutet nicht, dass es richtig ist. Dies verleiht FVA ein eher irreführendes Erscheinungsbild statistischer Strenge.
Selbst wenn das Unternehmen einen herkömmlichen Prognoseprozess mit minimalen menschlichen Berührungspunkten (siehe Abbildung 1) verwendet, ist die Analyse selbst eine Verschwendung, wenn die zugrunde liegende statistische Prognose, die von FVA analysiert wird, eine Zeitreihe ist.
Ironischerweise verschwenderisch
Als einmalige Demonstration von Überheblichkeit und voreingenommener Entscheidungsfindung besitzt FVA einen gewissen Nutzen. Nobelpreise wurden für die Tiefe, Breite und Beständigkeit kognitiver Verzerrungen in der menschlichen Entscheidungsfindung verliehen12 13, dennoch ist es durchaus denkbar, dass einige Teams nicht akzeptieren, wie fehlerhaft menschliche Übersteuerungen in der Regel sind, bis dies eindrücklich gezeigt wird.
Allerdings ist FVA als fortlaufendes Management-Tool von Natur aus fehlerhaft und, wenn man so will, widersprüchlich. Wenn die eigenen statistischen Prognosen von einer naiven Prognose und gemeinsamer Nachbesserung übertroffen werden, sollte man sich wirklich die folgende Frage stellen:
Warum scheitern die statistischen Modelle?
FVA hat hierfür leider keine Antwort, da es grundlegend nicht dafür ausgelegt ist. Es liefert keine Einsichten darüber, warum statistische Modelle unterdurchschnittlich abschneiden, sondern lediglich, dass sie es tun. FVA ist daher weniger ein Diagnosewerkzeug als vielmehr eine Lupe.
Auch wenn eine Lupe nützlich sein kann, liefert sie keine umsetzbaren Erkenntnisse darüber, was die tatsächlichen zugrunde liegenden Probleme der statistischen Prognosesoftware sind. Das Verstehen, warum die eigenen statistischen Prognosen unterdurchschnittlich abschneiden, hat weitaus größeren direkten und indirekten Wert und ist etwas, das FVA nicht deutlich zum Vorschein bringt.
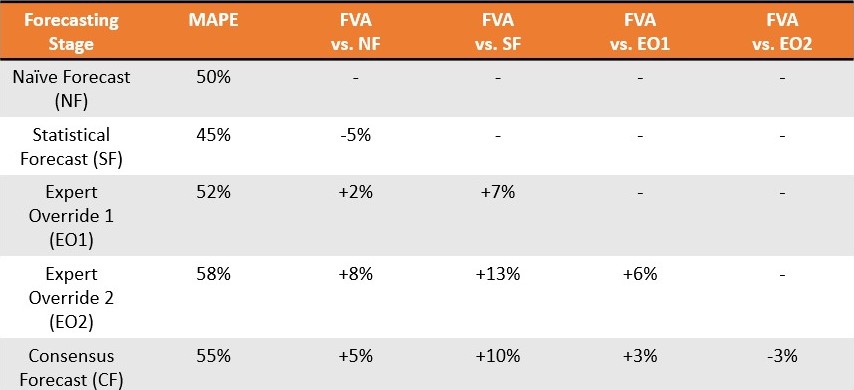
Nicht nur liefert die FVA-Software diese wichtige Erkenntnis nicht, sie formalisert Verschwendung auf andere Weise. Gilliland (2010) präsentiert eine theoretische Situation, in der eine Konsensprognose in 11 von 13 Wochen (85% Fehlerquote) übertroffen wird und im Durchschnitt 13,8 Prozentpunkte Fehler aufweist. Statt einer sofortigen Einstellung lautet der Rat,
“Bringen Sie diese Erkenntnisse zu Ihrem Management und versuchen Sie zu verstehen, warum der Konsensprozess diesen Effekt hat. Sie können damit beginnen, die Dynamik des Konsensmeetings und die politischen Agenden der Teilnehmer zu untersuchen. Letztlich muss das Management entscheiden, ob der Konsensprozess so verbessert werden kann, dass die Prognosegenauigkeit steigt, oder ob er abgeschafft werden sollte.”2
In diesem Szenario diagnostiziert die FVA-Software nicht das zugrunde liegende Problem der statistischen Prognoseleistung, sondern die Schicht der FVA-Instrumentierung erhöht lediglich die Bürokratie und Ressourcenallokation, indem sie Aktivitäten zerlegt, die offensichtlicherweise keinen Mehrwert leisten.
Die Installation einer FVA-Software-Schicht stellt somit sicher, dass man weiterhin ähnliche, niedrig aufgelöste Bilder eines fortdauernden Problems erhält und wertvolle Ressourcen darauf verwendet, fehlerhafte Eingaben zu verstehen, die von Anfang an hätten ignoriert werden können.
Dies ist, wie argumentiert werden könnte, nicht die weiseste Zuteilung von Unternehmensressourcen, die auch für andere Zwecke genutzt werden könnten.
Überschätzt den Wert von Genauigkeit
Im Kern geht FVA davon aus, dass eine erhöhte Prognosegenauigkeit es wert ist, isoliert verfolgt zu werden, und handelt auf dieser Grundlage, als wäre dies selbstverständlich. Die Vorstellung, dass eine höhere Prognosegenauigkeit wünschenswert sei, ist verständlich attraktiv, jedoch setzt sie – aus betriebswirtschaftlicher Sicht – voraus, dass eine größere Genauigkeit in höhere Rentabilität übersetzt wird. Dies ist eindeutig nicht der Fall.
Dies soll nicht heißen, dass eine genaue Prognose nicht von Wert ist. Vielmehr sollte eine genaue Prognose eng an eine rein finanzielle Perspektive gebunden sein. Eine Prognose könnte 40% genauer sein, doch die damit verbundenen Kosten bedeuten, dass das Unternehmen insgesamt 75% weniger Gewinn erzielt. Die Prognose, obwohl deutlich genauer (positiver Mehrwert), hat nicht die Fehler in Dollar reduziert. Dies widerspricht dem grundsätzlichen Prinzip des Geschäfts: mehr Geld zu verdienen oder zumindest keines zu verschwenden.
In Bezug auf FVA ist es durchaus denkbar, dass der positive Mehrwert, den eine Abteilung beisteuert, für ein Unternehmen ein Nettoverlust ist, während der negative Mehrwert einer anderen kaum wahrnehmbar ist. Obwohl Gilliland anerkennt, dass manche Aktivitäten die Genauigkeit erhöhen können, ohne finanziellen Wert hinzuzufügen, wird dieser Aspekt nicht bis zu seinem logischen Ende verfolgt: eine rein finanzielle Perspektive. Gilliland verwendet das Beispiel eines Analysten, der die Prognosegenauigkeit um einen einzigen Prozentpunkt erhöht:
“Allein die Tatsache, dass eine Prozessaktivität einen positiven FVA aufweist, bedeutet nicht zwangsläufig, dass sie im Prozess beibehalten werden sollte. Wir müssen den Gesamtnutzen der Verbesserung mit den Kosten dieser Aktivität vergleichen. Erhöht die zusätzliche Genauigkeit den Umsatz, senkt sie die Kosten oder macht sie die Kunden zufriedener? In diesem Beispiel reduzierte die Übersteuerung durch den Analysten den Fehler um einen Prozentpunkt. Aber es kann teuer sein, einen Analysten zu engagieren, der jede Prognose überprüft, und wenn die Verbesserung nur einen Prozentpunkt beträgt, ist das wirklich lohnenswert?”2
Anders ausgedrückt, ein Anstieg von 1% könnte sich nicht lohnen, aber ein größerer Anstieg der Prognosegenauigkeit könnte es wert sein. Dies setzt voraus, dass finanzieller Wert mit höherer Prognosegenauigkeit einhergeht, was nicht zwangsläufig der Fall ist.
Somit gibt es eine unausweichliche finanzielle Dimension in der Prognose, die im FVA höchstens unterbewertet (und im schlimmsten Fall kaum wahrgenommen) wird. Diese rein finanzielle Perspektive sollte wirklich die Grundlage sein, auf der ein Werkzeug zur Verringerung von Verschwendung aufgebaut ist.
Anfällig für Manipulation
FVA bietet auch eine offensichtliche Gelegenheit für Spielchen und Prognosemanipulation, insbesondere wenn die Prognosegenauigkeit als Maß für die Leistungsfähigkeit einer Abteilung herangezogen wird. Dies entspricht dem Geist von Goodharts Gesetz, welches besagt, dass sobald ein Indikator zum wichtigsten Erfolgsmaßstab wird (unbeabsichtigt oder absichtlich), dieser Indikator seinen Nutzen verliert. Dieses Phänomen kann oft den Weg für Fehlinterpretationen und/oder Manipulationen ebnen.
Angenommen, das Verkaufsteam erhält die Aufgabe, kurzfristige Anpassungen an der Nachfrageprognose auf Grundlage seiner Interaktionen mit Kunden vorzunehmen. Die Verkaufsabteilung könnte dies als Gelegenheit ansehen, ihren Wert zu signalisieren und beginnen, Änderungen an der Prognose vorzunehmen – auch wenn diese nicht notwendig sind –, um einen positiven FVA zu demonstrieren. Sie könnten die Nachfrage überbewerten, wodurch es so wirkt, als würden sie Wert generieren, oder die Nachfrage nach unten korrigieren, wodurch der Eindruck entsteht, sie würden eine zu optimistische Projektion einer vorangegangenen Abteilung berichtigen. So oder so könnte die Verkaufsabteilung für das Unternehmen wertvoller erscheinen. Infolgedessen könnte sich die Marketingabteilung dann ebenfalls gedrängt fühlen, den Anschein zu erwecken, Wert zu generieren, und das Team beginnt, ebenso willkürliche Anpassungen an der Prognose vorzunehmen (und so weiter).
In diesem Szenario wird das ursprünglich dazu gedachte FVA-Maß zur Verbesserung der Prognosegenauigkeit lediglich zu einem politischen Instrument, mit dem Abteilungen Wert signalisieren können, anstatt wirklichen Mehrwert zu schaffen, was auch von FVA-Befürwortern kritisiert wird9. Diese Beispiele verdeutlichen die potenziellen Gefahren von Goodharts Gesetz in Bezug auf FVA14.
Befürworter von FVA könnten argumentieren, dass diese psychologischen Kritiken den gesamten Punkt von FVA ausmachen, nämlich die Identifizierung von wertvollen versus minderwertigen Eingaben. Angesichts der heutzutage so gut verstandenen mit menschlicher Übersteuerung in der Prognose verbundenen Verzerrungen wäre es jedoch besser, die zur Analyse dieser verzerrten Eingaben aufgewendeten Ressourcen einem Prozess zuzuführen, der diese Eingaben von vornherein (soweit möglich) vermeidet.
Lokale Lösung für ein systemisches Problem
Implizit setzt der Versuch, die Nachfrageprognose isoliert zu optimieren, voraus, dass das Problem der Nachfrageprognose getrennt von anderen supply chain-Problemen ist. In Wirklichkeit ist die Nachfrageprognose komplex aufgrund des Zusammenspiels einer Vielzahl systemischer supply chain-Ursachen, einschließlich des Einflusses unterschiedlicher Lieferzeiten, unerwarteter supply chain-Störungen, Entscheidungen zur Lagerbestandszuweisung, Preisstrategien usw.
Der Versuch, die Nachfrageprognose isoliert zu optimieren (alias lokale Optimierung) ist ein fehlgeleiteter Ansatz, da die systemweiten Probleme – die wahren Ursachen – nicht richtig verstanden und angegangen werden.
Supply chain-Probleme – von denen die Nachfrageprognose sicherlich eines ist – sind wie Personen auf einem Trampolin: Bewegt man eine Person, entsteht ein Ungleichgewicht für alle anderen15. Aus diesem Grund ist eine ganzheitliche, durchgängige Optimierung besser, als zu versuchen, Symptome isoliert zu behandeln.
Lokads Sichtweise
Forecast Value Added nimmt eine schlechte Idee (kollaborative Prognose) und macht sie ausgefeilt, indem es die schlechte Idee in Schichten unnötiger Software kleidet und Ressourcen verschwendet, die besser anderweitig genutzt werden könnten.
Eine ausgefeiltere Strategie bestünde darin, über das gesamte Konzept der Prognosegenauigkeit hinauszublicken und stattdessen eine Risikomanagementpolitik zu wählen, die die Fehler in Dollar reduziert. In Verbindung mit einem probabilistischen Prognoseansatz entfernt sich diese Denkweise von willkürlichen KPIs – wie der Steigerung der Prognosegenauigkeit – und bezieht die Gesamtheit der eigenen wirtschaftlichen Treiber, Einschränkungen und potenziellen supply chain-Schocks in die Entscheidungsfindung über den Lagerbestand ein. Solche Risiko- (und Verschwendungs-) Vektoren können nicht effektiv quantifiziert (und eliminiert) werden durch ein Werkzeug, das eine kollaborative, Zeitreihenperspektive nutzt, wie sie beim Forecast Value Added zu finden ist.
Darüber hinaus vergrößert FVA – vielleicht unbeabsichtigt – durch die Trennung der Nachfrageprognose von der gesamt supply chain-Optimierung die zufällige Komplexität des Nachfrageprognoseprozesses. Zufällige Komplexität ist künstlich und resultiert aus der allmählichen Anhäufung unnötiger Störgeräusche – meist menschlichen Ursprungs – in einem Prozess. Das Hinzufügen redundanter Stufen und Software zum Prognoseprozess, wie es FVA tut, ist ein Paradebeispiel zufälliger Komplexität und kann das vorliegende Problem erheblich verkomplizieren.
Die Nachfrageprognose ist ein absichtlich komplexes Problem, das heißt, sie ist von Natur aus eine rätselhafte und ressourcenintensive Aufgabe. Diese Komplexität ist ein unveränderliches Merkmal des Problems und stellt eine weitaus beunruhigendere Herausforderung dar als zufällig komplexe Fragestellungen. Aus diesem Grund sollte man Lösungsansätze vermeiden, die das Problem vereinfachen und grundlegend fehlinterpretieren16. Um die medizinische Rhetorik der FVA-Literatur widerzuspiegeln: Es ist der Unterschied zwischen der Heilung einer zugrunde liegenden Krankheit und der ständigen symptomatischen Behandlung, sobald sie auftreten17.
Zusammenfassend existiert FVA im Spannungsfeld zwischen modernster supply chain-Theorie und der öffentlichen Wahrnehmung derselben. Eine intensivere Aufklärung über die zugrunde liegenden Ursachen der Nachfragesicherheit – und ihre Wurzeln in der sich entwickelnden supply chain Disziplin – wird empfohlen.
Anmerkungen
-
Forecast Value Added und Forecast Value Add werden verwendet, um dasselbe Analysewerkzeug der Prognose zu bezeichnen. Obwohl beide Begriffe weit verbreitet sind, besteht in Nordamerika eine vernachlässigbare Präferenz für letzteres (laut Google Trends). Michael Gilliland bezeichnete es jedoch ausdrücklich als Forecast Value Added in The Business Forecasting Deal – das Buch (und der Autor), das in Diskussionen über FVA am häufigsten zitiert wird. ↩︎
-
Gilliland, M. (2010). The Business Forecasting Deal, Wiley. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Gilliland, M. (2015). Forecast Value Added Analysis: Step by Step, SAS. ↩︎ ↩︎ ↩︎
-
Chybalski, F. (2017). Forecast value added (FVA) analysis as a means to improve the efficiency of a forecasting process, Operations Research and Decisions. ↩︎ ↩︎
-
Die Modellentabelle wurde von Schubert, S., & Rickard, R. (2011) adaptiert, Using forecast value added analysis for data-driven forecasting improvement. IBF Best Practices Conference. Der Stairstep-Bericht erscheint auch in Gillilands The Business Deal. ↩︎
-
John entschied sich für “All you need is apples” statt für das etwas ausführlichere “We can work it out…with apples”. ↩︎
-
Im vorliegenden Kontext ist delta ein Maß dafür, wie viel Fehler dem Forecast durch jedes Mitglied des Forecasting-Prozesses hinzugefügt wurden. Diese Verwendung des Begriffs unterscheidet sich etwas von delta im Optionshandel, der die Änderungsrate eines Optionspreises relativ zum Preis eines zugrunde liegenden Vermögenswerts misst. Beide Ausdrücke stehen insgesamt für Volatilität, aber der Teufel steckt im Detail. ↩︎
-
Der Leser wird aufgefordert, die Vorhersage der Apfelnachfrage durch die Vorhersage der Nachfrage für ein großes, globales Netzwerk von Geschäften – sowohl online als auch offline – zu ersetzen, von denen alle einen Katalog mit 50.000 SKUs besitzen. Die Schwierigkeit nimmt, wenig überraschend, exponentiell zu. ↩︎
-
Die Forecasting-Wettbewerbe von Spyros Makridakis, umgangssprachlich als die M-Wettbewerbe bekannt, laufen seit 1982 und gelten als höchste Autorität im Bereich modernster (und gelegentlich bahnbrechender) Forecasting-Methoden. ↩︎
-
Makridakis, S., Spiliotis, E., & Assimakopolos, V., (2022). M5 Accuracy Competition: Results, Findings, and Conclusions. Es sei erwähnt, dass nicht alle 50 leistungsstärksten Methoden ML-basiert waren. Es gab eine bemerkenswerte Ausnahme… Lokad. ↩︎ ↩︎
-
Die Arbeiten (sowohl einzeln als auch gemeinsam) von Daniel Kahneman, Amos Tversky und Paul Slovic stellen ein seltenes Beispiel für bahnbrechende wissenschaftliche Forschung dar, die auch in der breiten Öffentlichkeit Anerkennung gefunden hat. Kahnemans 2011er Thinking, Fast and Slow – das einen Großteil seiner 2002 mit dem Nobelpreis ausgezeichneten Forschung detailliert – ist ein Grundlagentext in der populärwissenschaftlichen Literatur und behandelt Entscheidungsfindungs-Biases in einem Ausmaß, das über den Rahmen dieses Artikels hinausgeht. ↩︎
-
Karelse, J. (2022), Histories of the Future, Forbes Books. Karelse widmet ein ganzes Kapitel der Diskussion kognitiver Verzerrungen im Kontext von Forecasting. ↩︎
-
Dies ist ein nicht unerheblicher Punkt. Abteilungen haben typischerweise KPIs, die sie erreichen müssen, und die Versuchung, Forecasts zu ihren eigenen Zwecken zu verzerren, ist sowohl verständlich als auch absehbar (Wortspiel beabsichtigt). Zum Kontext: Vandeput (2021, zuvor zitiert) stellt fest, dass das obere Management – der letzte Halt im FVA-Karussell – den Forecast möglicherweise bewusst verzerren kann, um Aktionäre und/oder Vorstandsmitglieder zufriedenzustellen. ↩︎
-
Diese Analogie stammt von der Psychologin Carol Gilligan. Gilligan verwendete sie ursprünglich im Kontext der moralischen Entwicklung von Kindern und der Wechselwirkung menschlichen Handelns. ↩︎
-
Es lohnt sich, hier einen Flagge zu setzen. Lösung(en) ist im Kontext absichtlicher Komplexität ein etwas unglücklicher Begriff. Tradeoff(s) – erhältlich in den Varianten besser oder schlechter – würde den delikaten Balanceakt, der mit der Bewältigung absichtlich komplexer Probleme verbunden ist, besser widerspiegeln. Ein Problem, bei dem zwei oder mehr Werte völlig im Widerspruch zueinander stehen, kann man nicht wirklich lösen. Ein Beispiel ist der Kampf zwischen Kostensenkung und dem Erreichen höherer Servicelevels. Da die Zukunft irreduzibel unsicher ist, gibt es keine Möglichkeit, die Nachfrage mit 100%iger Genauigkeit vorauszusagen. Man kann jedoch ein 100%iges Servicelevel erreichen – wenn dies die zentrale geschäftliche Zielsetzung ist – indem man einfach weit mehr Inventar lagert, als jemals verkauft werden könnte. Dies würde zu enormen Verlusten führen, weshalb Unternehmen – implizit oder anderweitig – akzeptieren, dass es einen unvermeidbaren Tradeoff zwischen Ressourcen und Servicelevel gibt. Somit stellt der Begriff “Lösung” das Problem unangemessen als eines dar, das gelöst werden kann, anstatt abgeschwächt zu werden. Siehe Thomas Sowells Basic Economics für eine ausführliche Analyse des Tauziehens zwischen rivalisierenden Tradeoffs. ↩︎
-
In The Business Forecasting Deal vergleicht Gilliland FVA mit einem Medikamentenversuch, bei dem naive Forecasts als Placebo fungieren. ↩︎