予測付加価値
予測付加価値1 (FVA) は、需要予測プロセスの各ステップ(および寄与者)のパフォーマンスを評価するためのシンプルなツールです。その究極の目的は、人為的介入(上書き)のうち予測精度を向上させないものを排除し、予測プロセスの無駄をなくすことにあります。FVAは、より高い予測精度を追求する価値があるとともに、精度を向上させる上書きを特定し、そうでないものを排除することが望ましいという考えに基づいています。善意にもかかわらず、FVAは一時的な利用に限定された効果しか示さず、継続的に運用されると、誤った数学的仮定、予測精度向上の内在的価値に関する誤解、そして堅牢な財務的視点の欠如など、数多くの欠点が露呈します。

予測付加価値の概要
予測付加価値は、営業、マーケティング、財務、運用等の需要計画以外の部門を含む複数の部門からのインプットを促し、評価することにより、無駄を排除し需要予測の精度を向上させることを目的としています。予測プロセスにおける各人為的介入の価値を評価することで、FVAは予測を悪化させる上書きに関する実用的なデータを企業に提供し、その結果、予測精度向上に寄与しない努力やリソースを特定して排除する機会を与えます.
マイケル・ギリランド、著書 The Business Forecasting Deal により本手法が広く注目されるようになった彼は2
“FVAは、コンピュータのハードウェアやソフトウェアから、アナリストや経営陣の時間とエネルギーに至るまで、予測プロセスに投資されたすべてのリソースが予測の改善に寄与していることを保証するのに役立ちます。これらのリソースが予測に貢献していない場合、安全により価値のある活動へと振り向けることができます”
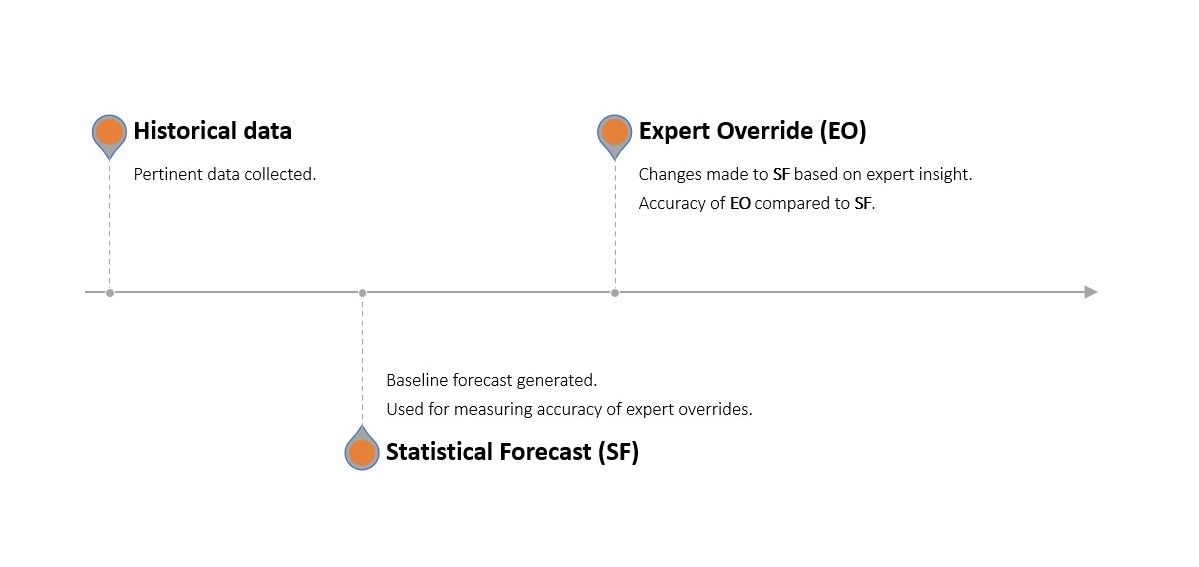
統計予測が、企業内の既存の予測ソフトウェアを用いて生成される多段階の予測プロセスを通じて、どの活動とリソースが_寄与しているか_を識別します。この統計予測は、その後、各部門による手動の変更(上書き)を受けます。この調整された予測は、変更が加えられていない(_プラセボ_として機能する)素朴なベンチマーク予測および実際の観測需要と比較されます.
各部門による変更が、変更前の統計予測と比較してより正確な結果をもたらした場合、それは正の価値を寄与したとみなされます。反対に、予測精度が低下した場合は負の価値となります。同様に、統計予測がプラセボよりも正確であれば正の価値が追加され、逆の場合はその反対となります.
FVAは、「予測プロセスの特定のステップまたは参加者に起因する予測性能指標の変化の尺度」2 であるといえます.
予測付加価値の支持者は、これが現代のサプライチェーン管理において不可欠なツールであると主張します。予測プロセスのどの部分が有益で、どの部分がそうでないかを特定することで、組織は予測精度を最適化することができます。全体的な論理は、予測の改善がより良い在庫管理、スムーズな生産計画、及びより効率的なリソース配分につながるというものです.
これにより、結果としてコストが削減され、品切れが最小限に抑えられ、過剰在庫が減少し、顧客満足度が向上するとともに、より包括的な予測と企業の姿勢が生まれるはずです。このプロセスは非常に人気があり、FVAはIntel、横浜ゴム、Nestle3など、極めて競争の激しい業界の注目すべき企業で採用されています。
予測付加価値分析の実施
予測付加価値分析の実施には、一般的に以下のような直感的な複数のステップが含まれます:
-
定義: 協議される部門のリスト、協議の順序、および各寄与者が初期予測を修正するために使用する特定のパラメーターを特定することにより、プロセスを定義します.
-
生成: ベンチマーク予測を生成します。このベンチマークは通常、素朴な予測の形を取り、会社内の通常の予測プロセスに従い、同じデータセットを用いて統計予測も生成され、これがその後のすべての調整の基盤となります.
-
収集: 指定された寄与者から、最初のステップで定義された正確なパラメーターに従ってインサイトを収集します。これには、市場動向の洞察、プロモーション計画、運営上の制約などが含まれる場合があります.
-
計算: 各寄与者について、その寄与前後の統計予測の精度を比較することでFVAを計算します。さらに、統計予測の精度は単純なベンチマーク予測と比較され、予測精度を向上させる寄与には_正のFVA_、精度を低下させる寄与には_負のFVA_が与えられます.
-
最適化: 負のFVAを示す寄与を改善または排除し、正のFVAを示す寄与を維持または強化することで最適化します.
これらのステップは、より高い予測精度を追求するために反復的に改善される継続的なプロセスを形成します。FVAプロセスと従来の予測プロセスとの違いは、以下に示されています.
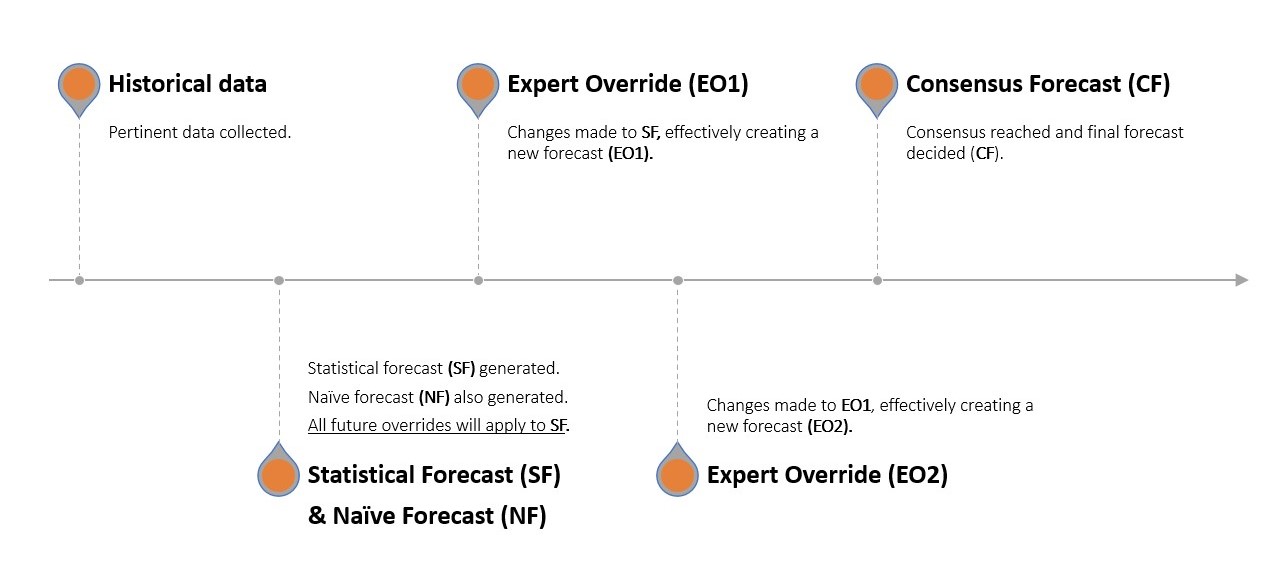
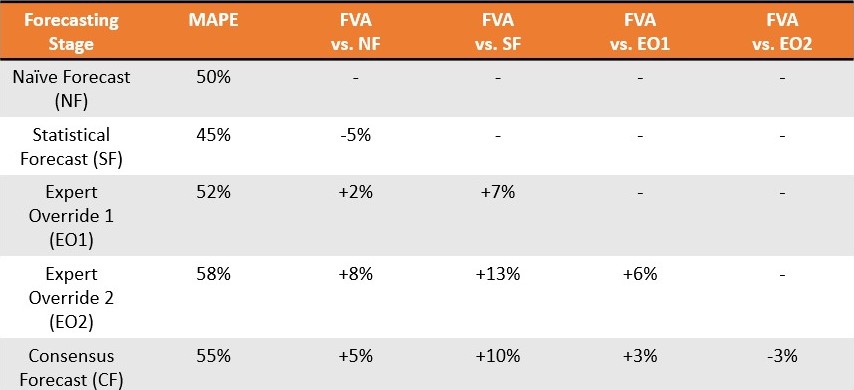
例えば、リンゴ販売業者を考えます。ポール(Demand Planning)は、過去3ヶ月それぞれで会社が8個のリンゴを販売したと経営陣に伝えます。Naïve Forecast は、翌月も8個が販売されると示唆しますが、ポールは先進的な統計ソフトウェアを用い、10個が販売されると予測する(Statistical Forecast)。ジョン(Marketing)は、今月、洗練された新スローガンを発表する意向であると6口を挟み、その鋭いウィットにより今月の売上がさらに増加すると予想します。ジョージ(Sales)は、リンゴをbundleして価格を若干下げ、売上をさらに刺激し需要を増加させようとします。リチャード(Operations)は当初途方に暮れたものの、重要なリンゴ仕分け機械の停止が迫っていることを踏まえ、予測需要を修正します。結果として、統計予測は手動で3回調整され、その後、各部門は口頭で合意予測に達するために集まりました.
1か月後、会社は各ステップでのデルタ7がどれほど大きかったか、つまり各部門の寄与がどれほど「ずれていたか」を確認するためにbacktestを実施します。これは、先月の実際の売上データを既に保有しており、ポールがジョン、ジョージ、リチャード各々、さらには合意予測段階8においてどの程度の誤差が生じたかを詳細に解析できるため、難しいことではありません.
予測付加価値における数学的視点
実際のところ、予測付加価値は非常に単純かつ意図的に複雑でないプロセスです。高度な数学的知識や統計的推論を必要とする予測プロセスとは対照的に、FVAは_「何かを行った場合と何もしなかった場合の結果を示す、理解しやすい常識的アプローチ」_3です.
しかしながら、何かを行った場合と行わなかった場合の結果を示すには数学的介入が必要であり、これは通常、単純な時系列となります。時系列は従来の予測方法とエクセルでの数式の根幹を成し、将来の需要を確率的予測定義として1つの実行可能な値で直感的に表現することを目的としています。FVAの文脈では、基準となる時系列がプラセボまたは対照として機能し、そこにすべてのアナリストによる上書き(前節で詳細に記述)が比較されます。基準時系列は、様々な方法、特に各種素朴予測の形で生成することができ、これらは通常、MAPE、MAD、MFEなどの指標を用いて評価されます.
ベンチマーク予測の選択
基準予測の選択は、対象となる企業の目標や制約に応じて異なります.
-
Naïve Forecastおよび季節性Naïve Forecast は、そのシンプルさからしばしば選ばれます。これらは、過去のデータが将来も繰り返されるという前提に基づくため、計算と理解が容易です。特にデータが比較的安定しているか、明確なパターン(トレンド、季節性、等)を示す場合に合理的な基準を提供します.
-
Random Walkおよび季節性Random Walk は、データが大きなランダム性や変動性を示す場合、または強い季節性パターンが存在しながらもランダムな変動が見られる場合に使用されます。これらのモデルは、未来の需要予測に内在する不確実性を反映するため、素朴な予測の概念に予測不可能性の要素を加えます.
予測付加価値結果の評価
-
MFE (平均予測誤差) は、予測が実際の結果を過大評価または過小評価する傾向を評価するために使用され、過大予測と過小予測のどちらがよりコストに影響するかが問題となる状況で有用です.
-
MAD (平均絶対偏差) および MAPE (平均絶対百分率誤差) は、需要の過大予測および過小予測の両方を考慮した予測精度の尺度を提供し、予測誤差の全体的な大きさを最小化することが重要な場合に使用されます.
MAPEはFVA関連の資料で一般的に取り上げられていますが、FVA分析においてどの予測指標の組み合わせを利用すべきかについては、意見が分かれています2 4 9.
FVAの限界
予測付加価値は、その包括的なアプローチ、高い目標、及び参入障壁の低さにもかかわらず、広範な限界や誤った前提に縛られていると主張できます。これらの欠点は、数学、現代予測理論、経済学など、さまざまな分野にまたがります.
予測は協働的ではない
予測付加価値は、複数の(場合によっては合意による)人為的上書きが_正の価値を加えることができる_という観点から、協働的な予測が優れているという考えに基づいています。さらに、FVAは、この正の予測価値が_企業全体に分散している_と信じ、異なる部門の従業員が将来の市場需要について貴重な洞察を持っていると考えています.
したがって、FVAが捉える問題は、この協働的アプローチにおいて、一部の人為的介入が負の価値をもたらすなどの厄介な非効率が伴う点にあります。FVAは、無駄な予測協力者の中から有用なものを見極めることを目指しています.
残念ながら、予測が協働的で複数部門にまたがるプロセスである方が優れているという考えは、現代の統計的予測(小売などの場合を含む)が示す結果と矛盾します.
第五回Makridakis予測コンペティション10の徹底的なレビューにより、“上位50の手法はすべてML(機械学習)に基づいていた。したがって、M5は、上位パフォーマンスのすべての手法がML手法であり、他のすべての統計的ベンチマークやその組み合わせよりも優れていた初のMコンペティションである” (Makridakis et al., 2022)11 が示されました。M5精度コンペティションは、世界最大の小売企業(Walmart)の歴史的データを用いて売上を予測することに基づいていました.
実際、Makridakis et al. (2022) によれば、"M5の勝者モデルは、予測に関する知識も販売予測モデル構築の経験もほとんどない学生によって開発された"11 ということで、異なる部門の市場洞察が予測の文脈においてどれほど重要であるかについて疑問が呈されています.
これは、より複雑な予測モデルが本質的に望ましいと主張しているわけではありません。むしろ、洗練された モデルはしばしば 単純な モデルに勝り、FVAの協働予測は複雑な問題に対する単純なアプローチです。
未来の不確実性を無視する
FVAは、他の多くの予測に関するツールや手法と同様に、未来(この場合は需要)の知識が時系列という形で表現できると仮定しています。通常は過去の販売実績を切り貼りしたコピーである単純な予測をベンチマークとして利用し、協力者が統計的予測の値を手動で丸め上げたり下げたりします。これは2つの理由で欠陥があります。
まず第一に、未来は、一般的な意味でも予測の意味でも、本質的に不確実です。そのため、未来を単一の値として表現するのは根本的に誤ったアプローチです(たとえ安全在庫計算式であっても)。本質的な未来の不確実性を前にすると、最も理にかなった方法は、各々の潜在的な財務リターンを評価した上で、考えられる未来値の範囲を決定することです。これはリスク管理の観点から、従来の時系列のように単一の値を特定しようとするよりも優れています―未来の不確実性という問題を完全に無視しているのです。
第二に、協力者の洞察(いくら有用に見えても)は、通常、時系列予測に簡単には(または全く)変換できないものです。例えば、ある企業がライバル企業が市場に参入しようとしていることを事前に把握している状況を考えてみてください。または、競合情報から、最も厳しい競争相手が印象的な新しい夏服ラインを発売しようとしている世界を想像してみてください。こうした洞察が、非専門家によって協働的に1つの値にまとめられるという命題は、空想的です。
実際、実際の未来の売上(正の価値追加)との類似性は全て偶然の産物であり、需要を上方または下方に丸めるという人間の上書き操作は、いずれも同じ誤った入力の表れにすぎません。つまり、マイナスの価値を寄与する人は論理的な観点から見ても、プラスの価値を寄与する人より「正しい」でも「間違っている」でもありません。
本質的にFVAは、三次元の特性(人間の洞察)を二次元の表面(時系列)に無理矢理押し付けようとしています。ある角度から見ると_正しく見える_かもしれませんが、それが_正しい_ことを意味するわけではありません。これにより、FVAは統計的厳密性の誤解を招く外観を持ってしまうのです。
たとえ企業が最小限の人間の介在による従来の予測プロセス(図1参照)を用いていたとしても、FVAが分析する基盤となる統計的予測が時系列であるなら、その分析自体は無駄な作業に過ぎません。
皮肉にも無駄な作業
過信と偏った意思決定の一度限りの実演として、FVAには一定の有用性があります。人間の意思決定における認知バイアスの深さ、広がり、そして持続性に対してノーベル賞が授与されたこともあります12 13が、強く示されるまでは、人間による上書き操作がいかに誤っているかを受け入れられないチームも存在するでしょう。
しかし、継続的な管理ツールとして見るなら、FVAは本質的に欠陥があり、むしろ矛盾していると言えます。もし統計的予測が単純な予測や協働による調整に敗れているなら、次の問いを真剣に考えるべきです:
なぜ統計モデルは失敗しているのか?
残念ながら、FVAはこの問いに対する答えを持っていません。根本的にそのために設計されていないのです。FVAは、統計モデルがなぜ低パフォーマンスになるのかという洞察を提供するのではなく、単にそれらが低パフォーマンスであるという事実を示すだけです。したがって、FVAは診断ツールというより拡大鏡に過ぎません。
拡大鏡が有用である場合もありますが、統計的予測ソフトウェアの根本的な問題が何であるかについて、実践的な洞察を提供することはできません。なぜ統計予測が低パフォーマンスに陥るのかを理解することは、直接的にも間接的にも非常に大きな価値があり、FVAはその点を明確にすることができません。
FVAソフトウェアはこの重要な洞察を提供しないだけでなく、他の方法で無駄を形式化します。Gilliland (2010) は、合意予測が13週間中11週間(85%の失敗率)で上回られ、平均で13.8ポイントの誤差となるという理論的な状況を提示しています。直ちに中止するのではなく、次のようなアドバイスがなされます:
“これらの知見を経営陣に伝え、なぜ合意プロセスがこのような影響を及ぼしているのか理解に努めてください。合意会議のダイナミクスや参加者の政治的議題を調査し始めることができます。最終的には、経営陣が合意プロセスを改善して予測精度を向上させることができるのか、それとも廃止すべきなのかを決定しなければなりません."2
このシナリオでは、FVAソフトウェアは統計予測パフォーマンスの根本的な問題を診断しないだけでなく、FVAの装置化レイヤーが、明らかに価値を生み出していない活動を細分化することによって、官僚主義とリソースの配分を増大させるだけなのです。
このように、FVAソフトウェアの層を導入することで、継続的な問題の低解像度な画像が得られ続け、最初から無視できたはずの誤った入力の理解に貴重なリソースが向けられてしまいます。
これは、他に利用可能な用途がある企業リソースの最も賢明な配分とは言えないでしょう。
精度の価値を過大評価する
本質的にFVAは、予測精度の向上を_孤立して_追求する価値があると仮定し、その前提のもとで物事を進めます。予測精度の向上が望ましいという考えは理解できる魅力的なものですが、ビジネスの観点からは、より高い精度がより大きな収益性に直結するとは限らないと考えられます。これは明らかにそうではありません。
これは、正確な予測が無価値であると主張しているのではありません。むしろ、正確な予測は純粋な財務的視点にしっかりと結びつけられるべきです。たとえば、予測精度が40%向上したとしても、関連コストのために企業の総利益が75%減少する可能性があります。予測は著しく正確になった(正の価値追加)としても、_誤差のドル削減_にはつながっていません。これは、より多くのお金を稼ぐか、少なくとも無駄にしないというビジネスの核心原則に反しているのです。
FVAの観点からは、ある部門による_正の価値追加_が企業全体にとって純損失であり、一方で別の部門による_負の価値追加_がほとんど感じられないという状況も十分に考えられます。Gillilandは、一部の活動が財務的価値を追加することなく精度を向上させる可能性があると認めていますが、この視点は論理的な結末、つまり**純粋な**財務的視点には至っていません。Gillilandは、あるアナリストが予測精度をたった1パーセントポイント向上させた例を挙げています:
“プロセスの活動が正のFVAを持っているという事実だけで、その活動をプロセスに残すべきだとは限りません。改善の全体的な利益とその活動のコストを比較する必要があります。追加の精度は収益を増加させ、コストを削減し、あるいは顧客をより満足させるのでしょうか? この例では、アナリストの介入により誤差が1パーセントポイント削減されました。しかし、すべての予測を見直すためにアナリストを雇うことは高額になり、改善がたった1パーセントポイントであるなら、本当にその価値があるのでしょうか?”2
言い換えれば、1%の向上は追求する価値がないかもしれませんが、_より大きな予測精度の向上_は追求する価値があるかもしれません。これは、財務的価値がより高い予測精度に結びついていると仮定していますが、必ずしもそうとは限りません。
したがって、予測には避けられない財務的側面が存在し、FVAでは_せいぜい_過小評価されているか、あるいは最悪の場合はほとんど注目されていません。この純粋な財務的視点こそが、無駄を削減することを目的としたツールの基盤であるべきです。
操作に対して脆弱
FVAはまた、予測精度が部門のパフォーマンス指標として用いられる場合、操作や予測の改ざんといった明白な隙をも提供します。これは、_Goodhartの法則_の精神そのものであり、一度指標が成功の主要な尺度(偶然か意図的に)となると、その指標は役に立たなくなるとされています。この現象は、誤解や操作への扉を開くことがよくあります。
例えば、営業チームが顧客との交流に基づいて需要予測に短期的な調整を加える任務を担ったとします。営業部門はこれを、自らの価値を示す機会と捉え、必要でなくとも予測に変更を加えて正のFVAを実証しようとするかもしれません。彼らは需要を過大に見積もって価値を生み出しているように見せるか、あるいは需要を下方修正して、以前の部門による過度に楽観的な予測を訂正しているように見せるかもしれません。いずれにしても、営業部門は企業にとってより価値のある存在に見えるでしょう。その結果、マーケティング部門もまた、価値を_見せる_ために圧力を感じ、同様に恣意的な予測の調整を始めることになるのです(以下、同様)。
このシナリオでは、当初予測精度を向上させるために意図されたFVAの指標が、部門ごとに価値を_示す_ための政治的メカニズムに転じ、実際に価値を_追加する_ものではなくなってしまいます。この点は、FVAの支持者でさえ認めています9。これらの例は、FVAにおいて_Goodhartの法則_がもたらす潜在的な危険性を示しています14。
FVAの支持者は、これらの心理的批判こそが_FVAの真髄_、すなわち_価値ある入力と無価値な入力の識別_であると主張するかもしれません。しかし、予測において人間の上書き操作に伴うバイアスが**今日では非常によく理解されている**ことを考えれば、これらのバイアスのある入力を詳細に分析するために投じられるリソースは、可能な限り最初からそのような入力を回避するプロセスに向けられるべきです。
システム的問題に対する局所的解決策
需要予測を孤立して最適化しようとする試みは、需要予測の問題が他のサプライチェーンの問題と_独立している_という前提に立っています。しかし実際には、需要予測は、変動するサプライヤーのリードタイム、予期せぬサプライチェーンの混乱、在庫配分の判断、価格戦略など、さまざまなシステム的要因の相互作用により複雑なのです。
需要予測を孤立して最適化しようとする試み(すなわち、局所最適化)は、システムレベルの問題―すなわち真の根本原因―が適切に理解され対処されていないことを踏まえると、誤ったアプローチです。
需要予測を含むサプライチェーンの問題は、まるでトランポリンの上に立つ人々のようなもので、一人が動くと全員に不均衡が生じます15。このため、症状を孤立して治療するのではなく、全体としてのエンドツーエンドの最適化が望ましいのです。
Lokadの見解
Forecast Value Addedは、悪いアイデアである協働予測を洗練されたものに見せかけ、不要なソフトウェアの層を纏わせ、本来より有用な代替用途があるリソースを浪費させます。
より洗練された戦略としては、予測精度という概念全体を超えて、むしろリスク管理方針―すなわち_誤差のドル削減_―を採用することが考えられます。確率的予測アプローチと併せ、この考え方は、予測精度の向上といった恣意的なKPIから離れ、企業の経済的推進要因、制約、そして潜在的なサプライチェーンショックの全体を在庫の意思決定に組み込むものです。この種のリスク(および無駄)を、協働的な時系列の視点に依拠するツール、すなわちForecast Value Addedで効果的に定量化(及び排除)することはできません。
さらに、需要予測を全体のサプライチェーン最適化から切り離すことで、FVAは(おそらく意図せずに)需要予測プロセスの偶発的複雑性を増大させます。偶発的複雑性とは、通常は人間由来の不要なノイズが徐々に蓄積された結果生じる人工的なものであり、FVAが行うように予測プロセスに冗長な段階やソフトウェアを追加することは、その典型例であり、当面の問題を著しく複雑化させる可能性があります。
需要予測は_意図的に複雑な問題_であり、すなわち本質的に不可解でリソースを大量に消費するタスクです。この複雑性は問題の不変の特性であり、偶発的な複雑性の問題よりもはるかに厄介な挑戦を意味します。したがって、問題の本質を過度に単純化し誤って解釈する解決策の試みは避けるべきです16。FVA文献の医療的レトリックを借りれば、これは根本的な病を治すことと、症状が現れるたびに対処することとの違いなのです17。
要するに、FVAは最先端のサプライチェーン理論と一般の認識との狭間に存在しています。需要の不確実性の根本原因―そして進化するサプライチェーン分野におけるその起源―について、より多くの教育が推奨されます。
注釈
-
Forecast Value Added と Forecast Value Add は、同じ予測分析ツールを指すために使われます。両者とも広く使用されていますが、北米では後者がわずかに好まれる傾向があります(Googleトレンドによると)。しかし、Michael Gillilandは『The Business Forecasting Deal』全体で明確に_Forecast Value Added_と呼んでおり、FVAに関する議論で最も引用される書籍(および著者)です。 ↩︎
-
Gilliland, M. (2010). The Business Forecasting Deal, Wiley. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Gilliland, M. (2015). Forecast Value Added Analysis: Step by Step, SAS. ↩︎ ↩︎ ↩︎
-
Chybalski, F. (2017). Forecast value added (FVA) analysis as a means to improve the efficiency of a forecasting process, Operations Research and Decisions. ↩︎ ↩︎
-
モデル表は Schubert, S., & Rickard, R. (2011). Using forecast value added analysis for data-driven forecasting improvement. IBF Best Practices Conference から適応されました。スターステップレポートは Gilliland の The Business Deal にも登場します。 ↩︎
-
Johnは、やや冗長な “We can work it out…with apples” よりも “All you need is apples” を選びました。 ↩︎
-
現在の文脈において、deltaは予測プロセスの各参加者によって予測に導入された誤差の大きさを測定する指標である。この用語の用い方は、基礎資産の価格に対するオプション価格の変化率を測るオプション取引におけるdeltaとはやや異なる。どちらも全体としてはボラティリティを表しているが、細部にこそ問題が潜む。 ↩︎
-
読者には、りんごの需要予測を、オンラインとオフラインの両方を有する世界規模の大規模店舗ネットワークの需要予測に置き換えることが提案されている。これらの店舗すべてが5万SKUのカタログを備えているため、当然ながら難易度は指数関数的に上昇する。 ↩︎
-
Spyros Makridakisが主催する予測コンペティション、通称M-コンペティションは、1982年より開催されており、最先端(時には極限まで革新的な)予測手法における圧倒的な権威と見なされている。 ↩︎
-
Makridakis, S., Spiliotis, E., & Assimakopolos, V., (2022). M5精度競争: 結果、所見、結論. 注目すべきは、上位50の手法すべてが機械学習ベースではなかったことである。ひとつの顕著な例外が存在した… Lokad. ↩︎ ↩︎
-
Daniel Kahneman、Amos Tversky、Paul Slovicの個々および共同の業績は、画期的な科学研究が主流の評価を受けた稀有な例を示している。Kahnemanの2011年の Thinking, Fast and Slow ― 2002年のノーベル賞受賞研究の大部分を詳細に記述している ― は、大衆科学の分野における基礎的なテキストであり、本稿の範囲を超えるほどの意思決定のバイアスを扱っている。 ↩︎
-
Karelse, J. (2022), Histories of the Future, Forbes Books. Karelse は、予測の文脈における認知バイアスの議論に丸ごと一章を充てている。 ↩︎
-
これは決して些細な点ではない。各部署は通常、達成すべきKPIを抱えており、自部門の都合に合わせて予測を操作しようとする誘惑は、理解可能であると同時に予見可能である(言葉遊びも込められている)。参考までに、Vandeput (2021, 前述) は、FVAサイクルの最終段階である上級管理職が、株主や取締役の支持を得るために意図的に予測を歪める可能性があると指摘している。 ↩︎
-
この類推は心理学者キャロル・ギリガンから引用されたものである。ギリガンは元々、子供の道徳的発達と人間行動の相互関係という文脈でこれを用いた。 ↩︎
-
ここで一石を投じる価値がある。意図的な複雑性の文脈では、Solution(s)(解決策)という呼称は誤解を招く。むしろ、Tradeoff(s) ― better(より良い)あるいは_worse_(より悪い)というバリエーションで表現される用語の方が、意図的に複雑な問題に対処する際の微妙な均衡をより適切に反映している。複数の価値が完全に対立する状況では、問題を真に_解決_することは不可能である。例えば、コスト削減と高いサービスレベルの実現との間の葛藤が挙げられる。未来が本質的に不確実である以上、需要を100%正確に予測する方法は存在しない。しかし、もしそれが主要なビジネス上の関心事であれば、販売不可能なほど多くの在庫を抱えることで100%のサービスレベルを実現することは可能である。しかしこの方法は莫大な損失を招くため、企業は暗黙の了解または明示的に、資源とサービスレベルとの間に_避けがたいトレードオフ_が存在することを受け入れている。したがって、「解決策」という用語は、問題が_解決_可能であるかのような誤った枠組みで捉えられており、本来は_緩和_されるべき問題であると指摘される。対立するトレードオフ間の綱引きについての詳細な分析は、Thomas Sowellの Basic Economics を参照のこと。 ↩︎
-
The Business Forecasting Deal において、GillilandはFVAを、無知な予測がプラセボとして機能する薬物試験に例えている。 ↩︎