Резервный запас (страховой запас)
Резервный запас - это метод оптимизации запасов, который показывает, сколько запасов нужно сохранить сверх ожидаемого спроса, чтобы достичь заданного уровня обслуживания. Дополнительный запас действует как “страховой” буфер - отсюда и название - чтобы защитить компанию от ожидаемых будущих колебаний. Формула резервного запаса зависит как от ожидаемого будущего спроса, так и от ожидаемого будущего времени доставки. Предполагается, что неопределенность нормально распределена для обоих факторов. Формула резервного запаса является всеобщей в большинстве систем управления запасами, включая наиболее известные ERP-системы и MRP-системы.
Обновление июль 2020 года: Подход, описанный ниже, является “классическим” подходом к управлению цепями поставок, однако он также является крайне дисфункциональным. В частности, будущий спрос и будущее время доставки не являются нормально распределенными (т.е. не являются гауссовыми). Более того, вся перспектива полностью упускает из виду тот факт, что все SKU, которые могут быть заказаны или произведены компанией, конкурируют за одни и те же ресурсы. Мы настоятельно рекомендуем не использовать никакую модель резервного запаса в реальных цепях поставок.
Целевая аудитория: Данный документ в первую очередь предназначен для специалистов в области управления цепями поставок в розничной торговле или производстве. Однако, данный документ также полезен для разработчиков программного обеспечения в области бухгалтерии, ERP-систем и электронной коммерции, которые хотели бы расширить свои приложения функциями управления запасами.
Мы постарались снизить математические требования до минимума, однако мы не можем полностью избежать всех формул, поскольку основная цель этого документа - быть практическим руководством, которое объясняет, как рассчитать резервный запас.
Скачать: calculate-safety-stocks.xls (Таблица Microsoft Excel)
Введение
Управление запасами - это финансовый компромисс между стоимостью запасов и дефицитом товара. Чем больше запасов, тем больше требуется оборотного капитала и больше ускоряется износ запасов. С другой стороны, если у вас недостаточно запасов, возникают дефициты товара, упущенные потенциальные продажи, возможность прерывания всего процесса производства.
Запасы зависят в основном от двух факторов.
- Спрос за время поставки: количество товаров, которые будут потреблены или куплены.
- Срок поставки: задержка между решением о пополнении запасов и возобновлением доступности.
Однако эти два фактора подвержены неопределенностям.
- Вариации спроса: поведение клиентов может развиваться в достаточно непредсказуемых направлениях.
- Вариации срока поставки: поставщики или транспортные компании могут столкнуться с неплановыми трудностями.
Принятие решения о уровне резервного запаса неявно эквивалентно нахождению компромисса между этими затратами с учетом неопределенностей.
Балансировка затрат на запасы и затрат на нехватку товара очень зависит от бизнеса. Вместо прямого учета этих затрат, мы сейчас введем классическое понятие уровня обслуживания.
Уровень обслуживания выражает вероятность того, что определенный уровень резервного запаса не приведет к нехватке товара. Естественно, при увеличении резервных запасов уровень обслуживания также увеличивается. Когда резервные запасы становятся очень большими, уровень обслуживания стремится к 100% (т.е. вероятность нехватки товара равна нулю).
Выбор уровня обслуживания, т.е. допустимой вероятности нехватки товара, выходит за рамки данного руководства, но у нас есть отдельное руководство по расчету оптимальных уровней обслуживания.
Модель пополнения запасов
Точка повторного заказа - это количество запасов, которое должно вызвать заказ. Если не было неопределенности (т.е. будущий спрос был бы точно известен, а поставка была бы абсолютно надежной), точка повторного заказа просто была бы равна общему прогнозируемому спросу за время поставки, также называемому спросом за время поставки.
На практике, из-за неопределенностей, у нас есть
точка повторного заказа = спрос за время поставки + резервный запас
Если мы предположим, что прогнозы не смещены (статистически говоря), то отсутствие резервных запасов приведет к уровню обслуживания 50%. Действительно, несмещенные прогнозы означают, что есть одинаковая вероятность того, что будущий спрос будет больше или меньше спроса за время поставки (помните, что спрос за время поставки - это просто прогнозируемое значение).
Осторожно: прогнозы могут быть несмещенными, но не точными. Смещение указывает на систематическую ошибку модели прогнозирования (например, всегда завышать спрос на 20%).
Нормальное распределение ошибки
На этом этапе нам нужен способ представления неопределенности в спросе за время поставки. В дальнейшем мы будем считать, что ошибка имеет нормальное распределение, см. рисунок ниже.
Статистические замечания: это предположение о нормальном распределении не является полностью произвольным. В определенных ситуациях статистические оценки сходятся к нормальному распределению, как указано в центральной предельной теореме. Но эти рассуждения выходят за рамки данного руководства.
Нормальное распределение определяется только двумя параметрами: его средним и дисперсией. Поскольку мы предполагаем, что прогнозы несмещенные, мы предполагаем, что среднее значение распределения ошибок равно нулю, что не означает, что мы предполагаем нулевую ошибку.
Определение дисперсии ошибки прогноза является более сложной задачей. Lokad, как и большинство инструментов прогнозирования, предоставляет оценки MAPE (Mean Absolute Percentage Error), связанные с его прогнозами. Для полноты картины мы объясним, как простые эвристики могут быть использованы для решения этой проблемы.
В частности, дисперсия внутри исторических данных может быть использована в качестве хорошей эвристики для оценки дисперсии ошибки прогноза. Дэвид Пиасеки также предлагает использовать прогнозируемый спрос вместо среднего спроса в выражении для дисперсии, то есть
где $$E$$ - оператор среднего, $$y_t$$ - исторический спрос за период $$t$$ (обычно объем продаж), а $$y’$$ - прогнозируемый спрос.
Основная идея этого предположения заключается в том, что ошибка прогноза очень часто коррелирует с ожидаемым уровнем вариации: чем больше предстоящие изменения, тем больше ошибка в прогнозах.
Фактически, вычисление этой дисперсии ошибки включает в себя несколько тонкостей, которые будут рассмотрены более подробно ниже.
Выражение для резервного запаса
На этом этапе мы определили как среднее, так и дисперсию, следовательно, известно распределение ошибок. Теперь нам необходимо рассчитать допустимый уровень ошибки в этом распределении. Здесь мы ввели понятие уровня обслуживания (в процентах), чтобы сделать это.
Примечания: Мы предполагаем статический срок поставки. Однако для изменяющегося срока поставки можно использовать очень похожий подход. См.
Чтобы преобразовать уровень обслуживания в уровень ошибки, также называемый фактор обслуживания, мы должны использовать обратное накопленное нормальное распределение (иногда также называемое обратным нормальным распределением) (см. NORMSINV для соответствующей функции Excel). Как может показаться сложным, на самом деле это не так, мы предлагаем взглянуть на приложение нормального распределения, чтобы получить более наглядное представление. Как видно, кумулятивная функция преобразует процент в площадь под кривой, порог по оси X соответствует значению фактора обслуживания.
Интуитивно мы вычисляем
резервный запас = стандартное отклонение ошибки * коэффициент обслуживания
Более формально, пусть $$S$$ будет резервным запасом, у нас есть
где $$\sigma$$ - это стандартное отклонение (т.е. квадратный корень из $$\sigma^2$$ дисперсии, определенной выше), $$cdf$$ - нормализованное накопленное нормальное распределение (с нулевым средним и дисперсией, равной единице), а $$P$$ - уровень обслуживания.
Помним, что
точка перезаказа = спрос за время доставки + резервный запас
Пусть $$R$$ будет точкой перезаказа, у нас есть
Сопоставление времени доставки и периода прогнозирования
До сих пор мы просто предполагали, что для заданного времени доставки мы могли непосредственно получить соответствующий прогноз будущего спроса. На практике это не совсем так. Анализ исторических данных обычно начинается с агрегации данных по временным периодам (обычно неделям или месяцам).
Однако выбранный период может не совпадать с временем доставки; поэтому требуются дополнительные вычисления для выражения спроса за время доставки и связанной с ним дисперсии (при условии, что мы все еще предполагаем нормальное распределение для ошибки прогноза, как подробно описано в предыдущем разделе).
Интуитивно спрос за время доставки может быть рассчитан как сумма прогнозируемых значений для будущих периодов, пересекающихся с временем доставки. Необходимо правильно скорректировать последний прогнозируемый период.
Формально, пусть $$T$$ будет периодом, а $$L$$ - временем доставки. Мы записываем
где $$k$$ - целое число, а $$0 ≤ α < 1$$. Пусть $$D$$ будет спросом за время доставки. Тогда у нас есть окончательное выражение для спроса за время доставки
где $$y’_n$$ - это прогнозируемый спрос для $$n$$-го периода в будущем.
Учитывая те же предположения о нормальном распределении, мы можем вычислить дисперсию ошибки прогноза как
где $$y’$$ - средний прогноз на период
Однако $$\sigma^2$$ вычисляется здесь как дисперсия на период, тогда как нам нужна дисперсия, соответствующая времени доставки. Пусть $$\sigma_{L}^2$$ будет скорректированной дисперсией на время доставки, у нас есть
Наконец, мы можем переопределить точку перезаказа как
Использование Excel для вычисления точки перезаказа
В этом разделе подробно описывается как рассчитать точку перезаказа с помощью Microsoft Excel. Мы предлагаем взглянуть на образец электронной таблицы Excel, предоставленный нами.
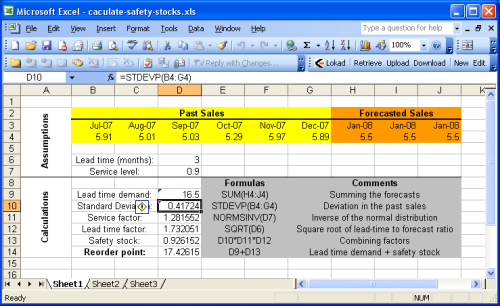
Образец таблицы в основном разделен на две части: предположения сверху и вычисления внизу. Прогнозы предполагаются частью предположений, потому что прогнозирование продаж (или спроса) выходит за рамки данного руководства. Вы можете обратиться к нашему руководству по прогнозированию продаж с помощью Microsoft Excel для получения подробной информации.
Большинство формул, представленных в предыдущем разделе, являются очень простыми операциями (сложение, умножение), которые очень легко выполнять с помощью Microsoft Excel. Однако, две функции заметны:
- NORMSINV (Microsoft KB): оценивает накопленное нормальное распределение, обозначенное здесь как cdf.
- STDEV (Microsoft KB): оценивает стандартное отклонение, обозначенное $$σ$$ выше. Мы напоминаем, что стандартное отклонение $$σ$$ является квадратным корнем из дисперсии $${σ^2}$$.
Для упрощения, на первом листе не реализован эвристический подход $${σ^2 = E[ (y_t - y’)^2 ]}$$ при расчете коэффициента обслуживания. Этот подход реализован в Sheet2 (вторая электронная таблица документа Excel). Поскольку мы предположили стационарные прогнозы в примере, точка перезаказа остается идентичной с или без этого эвристического подхода.
Ресурсы
Управление запасами и планирование производства, Эдвард А. Сильвер, Дэвид Ф. Пайк, Рейн Петерсон, Wiley; 3-е издание, 1998