Приоритетное пополнение запасов в Excel с вероятностными прогнозами
Неопределённость — это неустранимая составляющая прогнозирования. Тем не менее, в XX веке статистическое прогнозирование появилось с надеждой, что при наличии адекватных математических моделей неопределённость можно устранить. В результате ранние теории цепочки поставок умалчивали или отвергали неопределённость, так как ожидалось, что новые или лучшие методы прогнозирования позволят её устранить или, в противном случае, сделать её несущественной. Хотя намерения были благими, эти подходы оказались ошибочными, поскольку неопределённость, спустя век статистического моделирования, остаётся по своей природе неустранимой. В 2012 году компания Lokad предложила альтернативный подход к управлению цепями поставок, который принимает и количественно оценивает неопределённость. Этот подход использует вероятностные прогнозы вместо классических точечных временных рядов. В данном руководстве, а также в прилагаемой Excel-таблице, мы применяем вероятностные прогнозы для решения проблемы пополнения запасов. Такой подход приводит к формированию политики приоритетного пополнения запасов, наглядно продемонстрированной в Excel. Наша задача двояка: во-первых, сделать этот подход популярным среди аудитории, которая может не чувствовать себя комфортно с более продвинутыми программными инструментами; во-вторых, продемонстрировать, что принятие неопределённости требует определённого образа мышления больше, чем сложных инструментов.
Скачать: probabilistic-inventory-replenishment.xlsx
1. Проблема пополнения запасов
Проблема пополнения запасов заключается в определении оптимального списка закупок – такого, который учитывает основные финансовые ограничения и цели компании. Метод формирования такого списка должен одинаково эффективно работать вне зависимости от бюджетных ограничений, поскольку он нацелен на максимизацию возврата инвестиций для каждого потраченного доллара. Проблема состоит в том, что все SKU конкурируют за одни и те же средства, поэтому финансовая отдача от хранения каждой конкретной единицы SKU должна быть количественно оценена и ранжирована в контексте всех дополнительных единиц каждого SKU.
1.1 Решение для приоритетного пополнения запасов
Процесс ранжирования запасов, описанный выше, требует микроскопического подхода. Чтобы сравнить отдачу от добавления конкретной единицы SKU в список закупок, необходимо учесть несколько факторов. А именно, вероятность её продажи, предоставляемая вероятностным прогнозом спроса, и экономические драйверы — например, валовая прибыль и закупочная цена. Каждое рассматриваемое количество, в свою очередь, должно быть сбалансировано с учетом внутренних и внешних ограничений (таких как ограниченная складская вместимость, множители партий и MOQ/MOV и т.д.). Краевые случаи, когда две (или более) единицы имеют равную ожидаемую прибыльность, должны быть учтены в политике пополнения запасов посредством оценки относительной важности каждого продукта. SKU не следует рассматривать поодиночке, а необходимо группировать их в корзины. Некоторые SKU, несмотря на более низкую маржу в отдельности (например, молоко), имеют большее значение, так как они обеспечивают продажи товаров с высокой маржой. Таким образом, финансовая отдача за поддержание уровня сервиса для товара с более низкой маржой – продукта, способствующего другим продажам – представляет собой дополнительный драйвер («stockout cover”)1. Подход приоритетного пополнения запасов (ППЗ), использующий вероятностное прогнозирование в качестве входных данных, учитывает все перечисленные факторы.
Короче говоря, решение ППЗ можно свести к трем шагам:
1. Построить вероятностный прогноз спроса.
2. Составить список всех допустимых количеств закупок.
3. Ранжировать все допустимые количества закупок с учетом экономических драйверов.
1.2 Приоритетное пополнение запасов в Excel
Используя финансовые данные вымышленного магазина, включая экономические драйверы, упомянутые в предыдущем разделе, данная Excel-таблица моделирует политику пополнения запасов для трех SKU (ручки, клавиатуры и книжные шкафы)2. Финансовые последствия каждой дополнительной единицы SKU (если ее заказать) и вероятность её продажи иллюстрированы на листе Диаграммы (см. Рисунок 1). Диаграммы и графики обновляются в зависимости от входных данных и предположений модели (например, начальные уровни запасов, цены закупки и продажи и т.д.) на листе Контрольная башня (Рисунок 2). Подробный список допустимых вариантов решений создается на листе Микро закупочные решения (Рисунок 3) на основе ключевых входных данных. Эти данные — вероятностные прогнозы спроса с листа «Генераторы распределения» (Рисунок 4) и информация с листа Контрольная башня. Наконец, сводная таблица приоритетных решений по пополнению запасов составляется и ранжируется в порядке ожидаемой отдачи от инвестиций (см. лист Ранжированные закупочные решения на Рисунке 5).
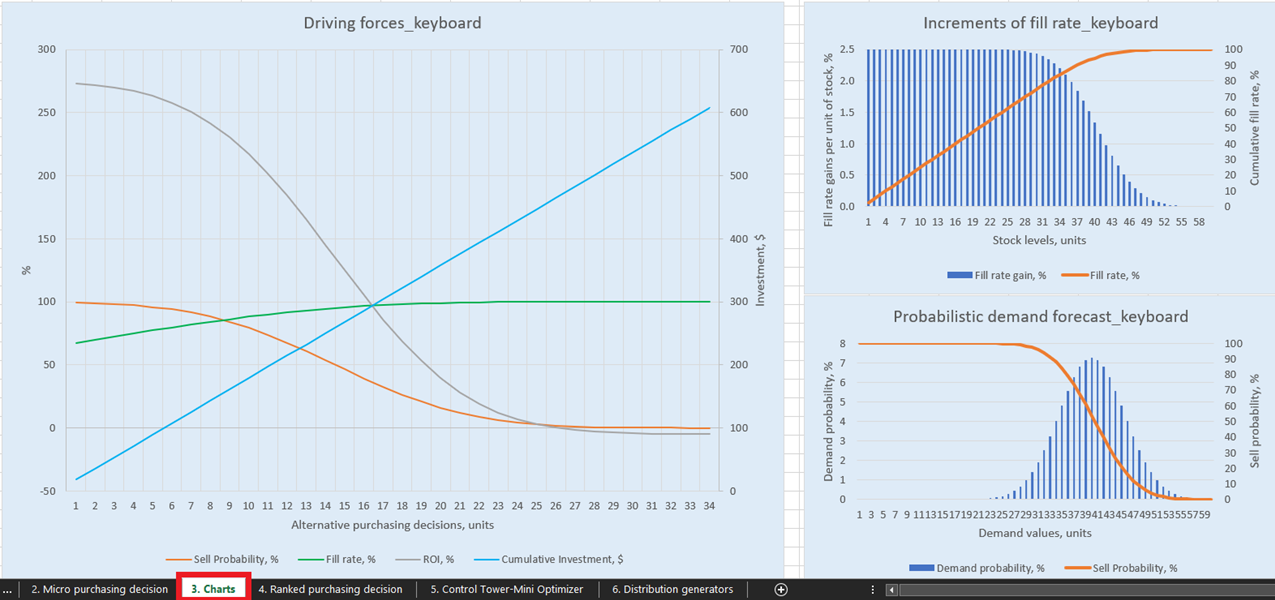
Рисунок 1. Вид «Клавиатуры драйверов» в Диаграммах, место выделено красным.
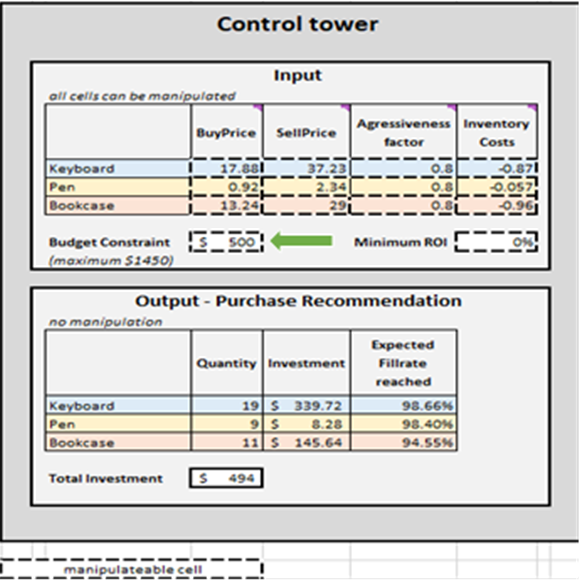
Рисунок 2. Вид «Контрольной башни», расположенной в Контрольной башне – Mini Optimizer (лист 5). Значение «Бюджетное ограничение» можно изменять от $0 до $1450 (см. зеленую стрелку).
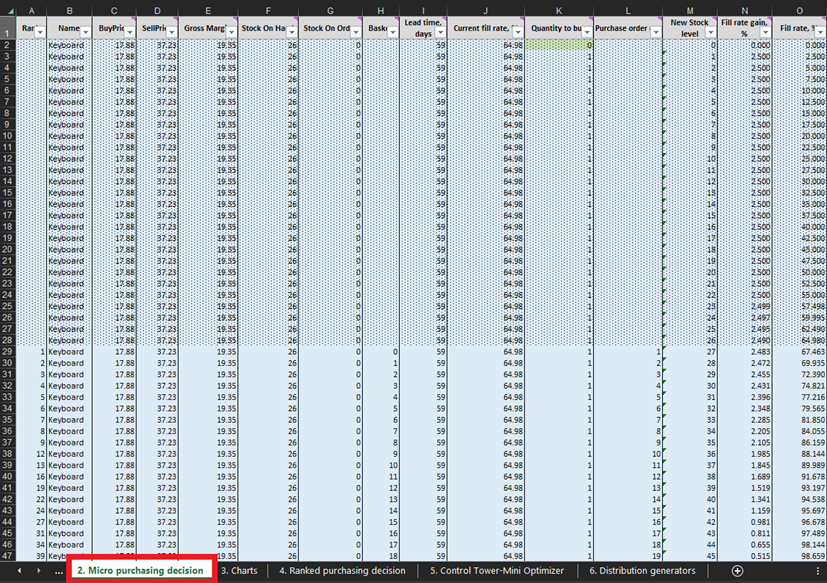
Рисунок 3. Расположение Микро закупочных решений в Excel, выделено красным. Строки, оформленные условно-точечным форматированием, представляют собой исторические данные (до 28-й строки включительно, как на изображении выше). Эти данные отражают предыдущие решения по закупкам. Нас интересует только всё, что находится ниже этого форматирования. Тот же стиль оформления применяется к данным о ручках и книжных шкафах.
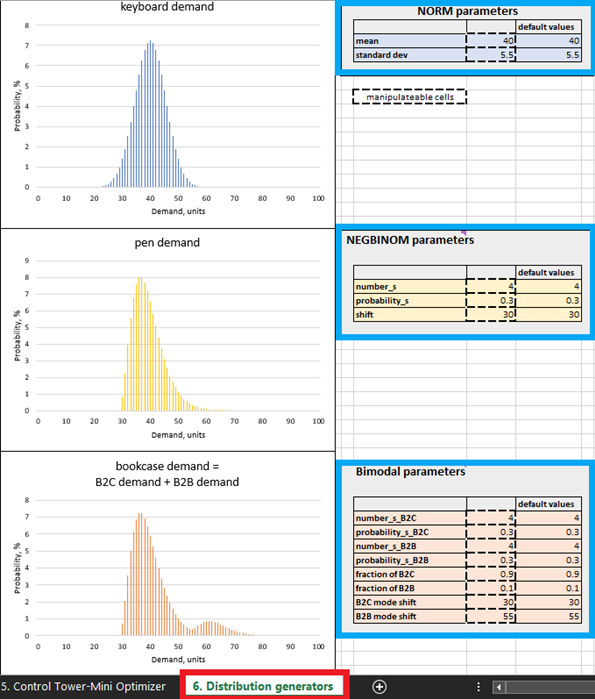
Рисунок 4. Расположение Генераторов распределения в Excel, выделено красным. Панели управления продуктом выделены синим. Ячейки с пунктирными рамками можно изменять.
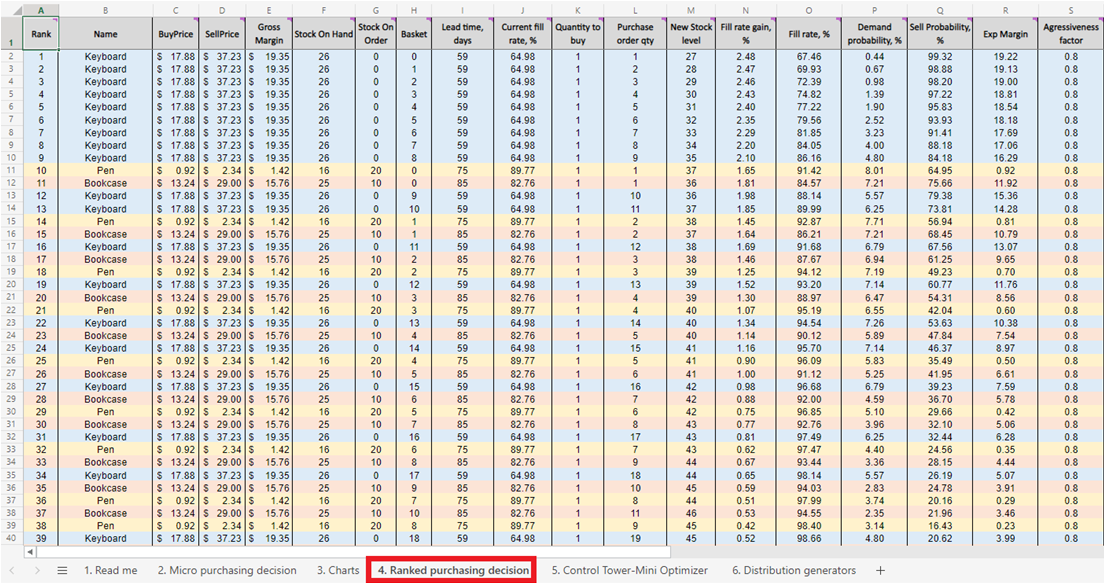
Рисунок 5. Список приоритетных решений по пополнению запасов, основанных на микро закупочных решениях, расположенный на листе 4.
2. Вероятностный прогноз спроса
В данном контексте вероятностный прогноз — это совокупность всех вероятных значений будущего спроса и их соответствующих вероятностей. Он включает в себя присущую неопределённость будущего спроса и может быть построен на любой временной интервал. Подобно традиционному прогнозу временного ряда, выделяется одно, наиболее вероятное значение спроса (белые точки на Рисунке 6) и линия тренда (серая линия, соединяющая белые точки). Однако вероятностный прогноз интегрирует неопределённость, включая все возможные (хотя и не равновероятные) значения спроса. Такой подход можно увидеть на Рисунке 6, где различные доверительные интервалы представляют значения спроса с разными вероятностями.
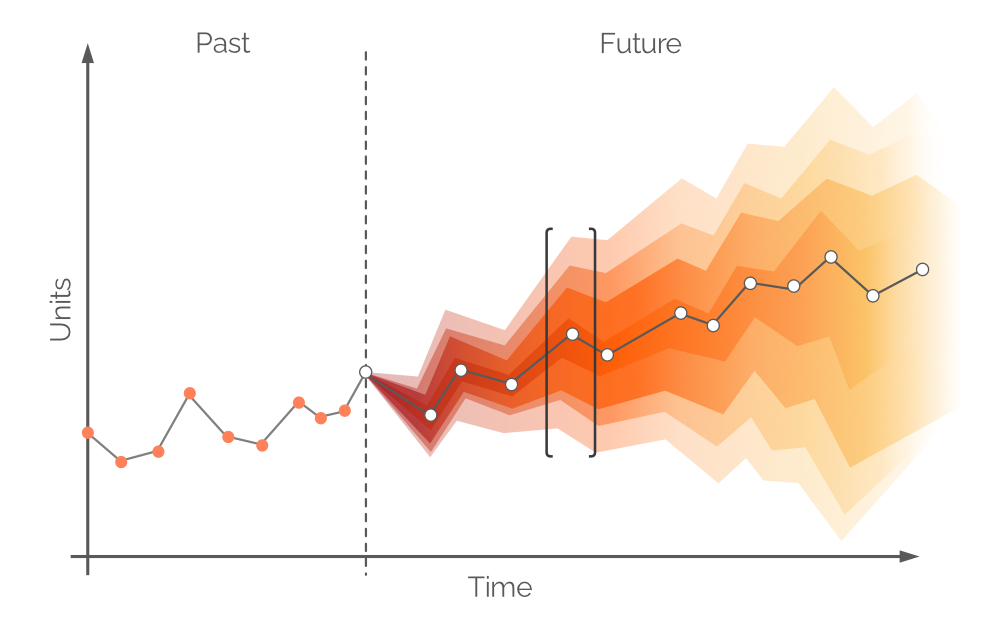
Рисунок 6. Вероятностный прогноз (спрос по оси Y; время по оси X). Пунктирная вертикальная серая линия указывает на текущий момент («сейчас»). Время измеряется в днях, хотя это может быть любой желаемый интервал. Область в черных скобках обсуждается далее.
Белые точки на Рисунке 6 представляют наиболее вероятные значения спроса в фиксированные будущие интервалы. Рядом расположена цветовая полоса, соответствующая диапазону альтернативных значений спроса — цветное представление функции распределения вероятностей. Цвет становится менее насыщенным по вертикали по мере удаления от белой точки, что указывает на большую неопределённость и меньшую вероятность. В целом, цветовые полосы тускнеют по мере продвижения времени (по горизонтали), поскольку неопределённость усиливается с течением времени. Однако, независимо от неопределённости, всегда существует хотя бы одно значение, которое является наиболее вероятным, и оно всегда обозначается белыми точками. Пример распределения вероятностей для одной временной точки показан на Рисунке 7.
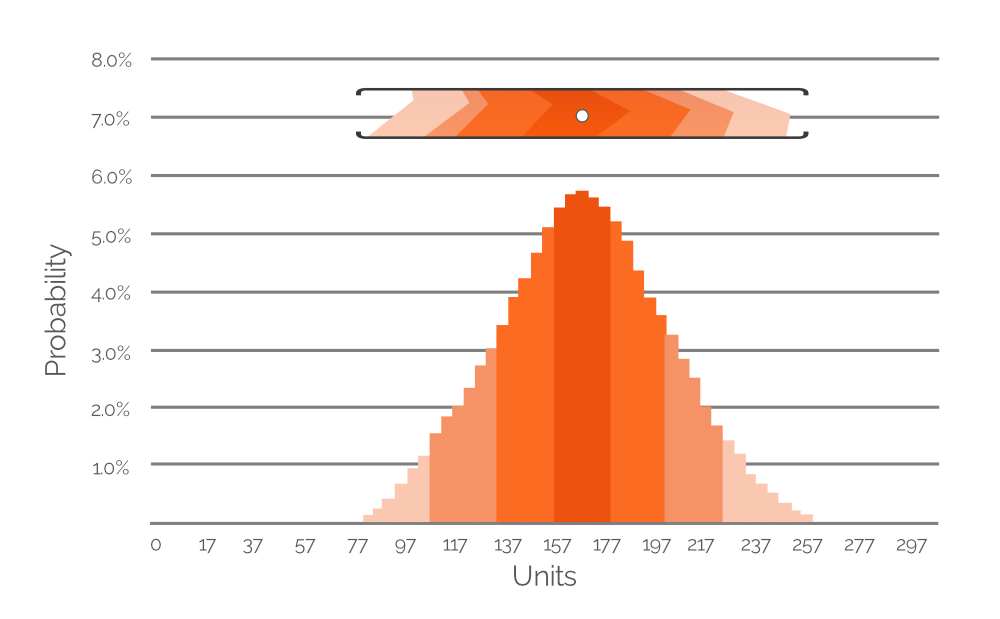
Рисунок 7. Гистограмма, демонстрирующая вероятность нескольких возможных значений спроса (с интервалом в 20 единиц). Ось Y — значение вероятности; ось X — спрос в единицах. Гистограмма представляет собой отображение выделенного диапазона значений на Рисунке 6 (приведена для справки).
Рисунок 7 представляет выделенные данные с Рисунка 6 в виде гистограммы вероятностей с явными числовыми значениями, обозначающими вероятность различных значений спроса. Цветовое кодирование сохранено для удобства восприятия (помните, что менее насыщенные цвета означают меньшую вероятность, а более плотные — большую). В данном примере наиболее вероятное значение спроса составляет 167 единиц (+/-), поэтому белая точка в обрезанном диапазоне значений с Рисунка 6 расположена непосредственно выше самой высокой полосы гистограммы. Однако, мы также назначаем вероятности спроса для крайне низких и высоких значений (примерно 80 и 260 единиц соответственно, оба оттенка очень бледного оранжевого). Это демонстрирует потенциальное богатство данных вероятностного прогноза, и аналогичные гистограммы включены в Excel-таблицу — по одной для каждого нашего SKU (см. Рисунок 4). Используя эти гистограммы (как на Рисунке 7 выше), можно определить значения спроса (в единицах) с ненулевой вероятностью наступления и учесть их в ППЗ.
2.1 Построение вероятностного прогноза
Хотя возможно построить настоящий вероятностный прогноз с использованием исторических данных в Excel, этот инструмент, пожалуй, является наименее подходящим для данной задачи. В целом, специфические детали построения промышленного уровня вероятностного прогноза выходят за рамки данного документа, поэтому для простоты были выбраны синтетические вероятностные прогнозы. Параметрами этих синтетических прогнозов можно управлять на листе Генераторы распределения (см. Рисунок 4). Однако рекомендуется сначала изучить настройки по умолчанию, прежде чем вносить изменения.
В общепринятых практиках управления цепями поставок спрос обычно считается нормально распределённым, однако это скорее исключение. В реальных цепочках поставок большинство SKU отклоняются от нормального распределения. Учитывая эту действительность, мы сознательно выбрали три различных типа распределения: нормальное (для клавиатур), отрицательное биномиальное (для ручек) и бимодальное (для книжных шкафов — смесь двух отрицательных биномиальных распределений). Далее приводится обоснование для такого предположения.
Например, мы предполагаем, что книжные шкафы приобретаются как частными лицами, так и компаниями (например, школами), поэтому для них используется бимодальное распределение. В настройках по умолчанию для книжных шкафов спрос со стороны частных лиц выражается часто – покупается по одной или двум единицам на клиента. Это представляет первый мод распределения (см. Рисунок 4). Компании, напротив, являются менее частыми источниками спроса, но делают более крупные заказы (больше, чем у частных лиц). Когда это происходит, их спрос добавляется к спросу, генерируемому покупками частных лиц, и появляется второй мод распределения. Этот второй мод смещается вправо (что означает высокие значения спроса) и заметно меньше первого мода, что отражает его меньшую частоту (Рисунок 4). Наша модель также предполагает, что ручки приобретаются частными лицами с редкими всплесками высокого спроса (например, студенты, покупающие перед экзаменами). Наконец, чтобы отразить тот факт, что нормальное распределение иногда встречается, продажи клавиатур следуют нормальному распределению.
На листе Генераторы распределения (Рисунок 4) можно отредактировать распределения спроса, изменяя параметры в ячейках, доступных для редактирования. Например, увеличение среднего значения для клавиатур (см. «Параметры NORM» на Рисунке 4) с 40 до 50 приведёт к смещению распределения на 10 единиц вправо. В результате этого увеличения среднего спроса ожидаемая рентабельность инвестиций для всех единиц клавиатур возрастёт. Аналогичным образом можно внести изменения в параметры отрицательного биномиального (ручки) и бимодального (книжные шкафы) распределений.
Так как Excel не обладает достаточной выразительностью для подобных вычислений, в данной демонстрации изменения ограничены 100 единицами на продукт. Например, установка среднего значения для клавиатур на 99 приведёт к тому, что почти 50% единиц спроса не будут учтены на листе Микро закупочные решения.
2.2 Выбор горизонта для вероятностного прогноза спроса
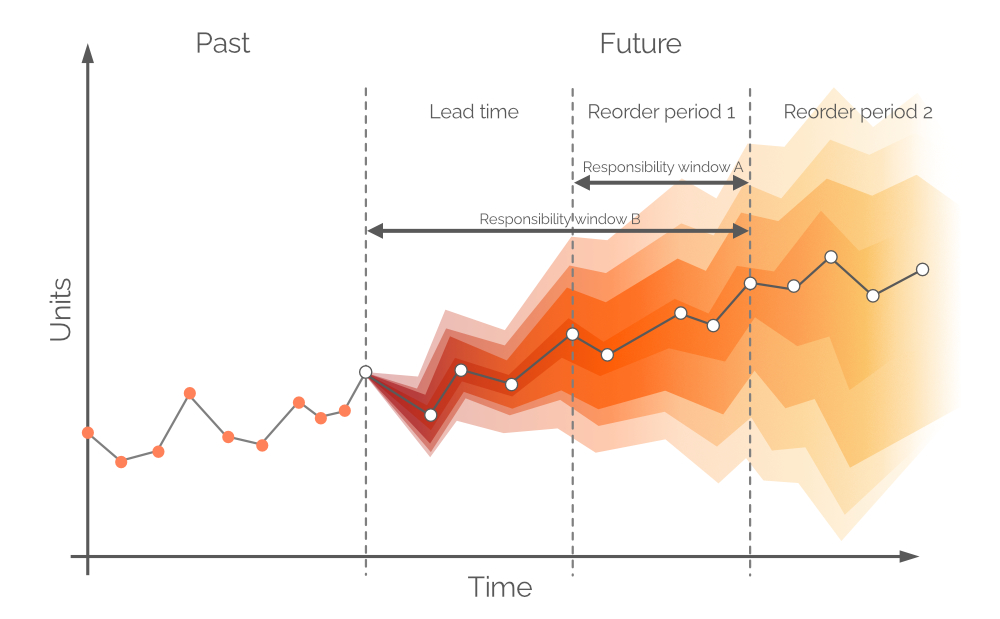
Обычно прогнозы делят на ежедневные/недельные/месячные интервалы, хотя эти дискретные периоды имеют ограниченную полезность и ценность с точки зрения пополнения запасов. Спрос на следующий срок поставки не может быть удовлетворён решениями о закупках, принятыми сегодня, если не разрешены предзаказы, поскольку любые приобретённые единицы поступят после периода, равного сроку поставки. Таким образом, спрос должен удовлетворяться за счёт текущих запасов магазина и заказанных запасов (см. Рисунок 8), при условии, что единицы, находящиеся в статусе заказа, поступят до наступления спроса. Поэтому вероятностный прогноз касается спроса между точками повторного заказа или, другими словами, спроса в течение Периода повторного заказа 1 (см. Рисунок 9). Более отдалённый будущий спрос будет удовлетворяться будущими заказами (см. Период повторного заказа 2, на Рисунке 9).

Рисунок 8. Текущие запасы (столбец F) и Заказанные запасы (столбец G), выделенные красным, находятся в разделе Микро решения по закупкам. Срок поставки, столбец I, выделен синим.
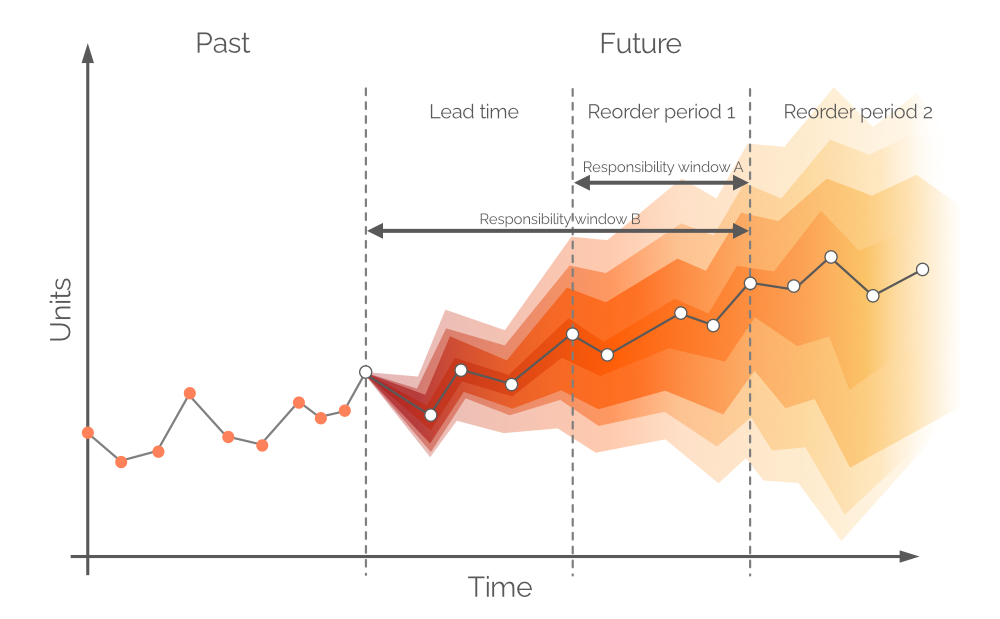
Рисунок 9. Визуальное изображение альтернативных окон ответственности. Спрос отложен по вертикальной оси, время – по горизонтальной, при этом пунктирная вертикальная серая линия слева указывает на текущий момент («сейчас», как на Рисунке 6). Вероятностный прогноз, представленный в данном документе, касается спроса в горизонте, равном Окну ответственности B.
Теоретически, вероятностный прогноз спроса должен строиться на временном интервале, равном Периоду повторного заказа 1 – этот интервал обозначается как Окно ответственности A (см. Рисунок 9). Для этого необходимо сделать прогнозы будущих текущих запасов и заказанных запасов по окончании срока поставки. Однако спрос за время поставки – по которому мы уже приняли решения в предыдущем периоде заказа – также является вероятностным, и это приведёт к тому, что уровни запасов сами будут распределениями вероятностей3. Допуская предзаказы (распространённая практика в некоторых отраслях) вероятностный прогноз можно построить на общем периоде (Срок поставки плюс Период повторного заказа 1, см. Рисунок 9, также известный как Окно ответственности B).
Можно предположить, что текущие уровни текущих запасов и заказанных запасов удовлетворят спрос в течение периода срока поставки. Если произойдёт событие дефицита товара, то любой последующий спрос будет покрыт предзаказами. Эти предзаказы будут выполнены на основе микро решений по закупкам, принятых на сегодняшний день. Это позволяет нам рассматривать текущие запасы и заказанные запасы как дискретные значения (а не как случайные)4.
3. Определение допустимых вариантов решений о пополнении запасов
В реальной ситуации пополнения запасов необходимо определить все возможные варианты решений, поскольку нет однозначного способа перейти от вероятностного прогноза к единственному оптимальному решению (количеству закупки, в данном случае) для каждого продукта. Вместо единственного идеального выбора, вероятностный подход предлагает спектр возможных решений, которые необходимо оценить с точки зрения допустимости.
Допустимость здесь означает, что решение может быть немедленно выполнено; его можно реализовать «как есть» без проведения дополнительных вычислений или проверок. Например, решение считается «допустимым», если оно приносит прибыль и удовлетворяет всем нашим ограничениям (например, минимальный объём заказа, экономичный объём заказа (EOQ), размеры партий, полные контейнерные перевозки и любым другим ограничениям, которые могут существовать в нашей цепочке поставок)5.
На каждой строке листа Микро решения по закупкам (Рисунки 3 и 10) мы должны рассматривать возможность добавления ещё одной единицы товара к нашему заказу для конкретного продукта6. Наш «настоящий момент» (или День 1 этого эксперимента) начинается со строки 29, которая показывает текущий уровень запасов. Он рассчитывается как сумма текущих запасов и заказанных запасов. Если мы решим добавить единицу к заказу, то общее количество закупаемых единиц будет вычислено в столбце L как сумма всех ранее рассмотренных единиц для закупки (см. примечания к Рисунку 10).
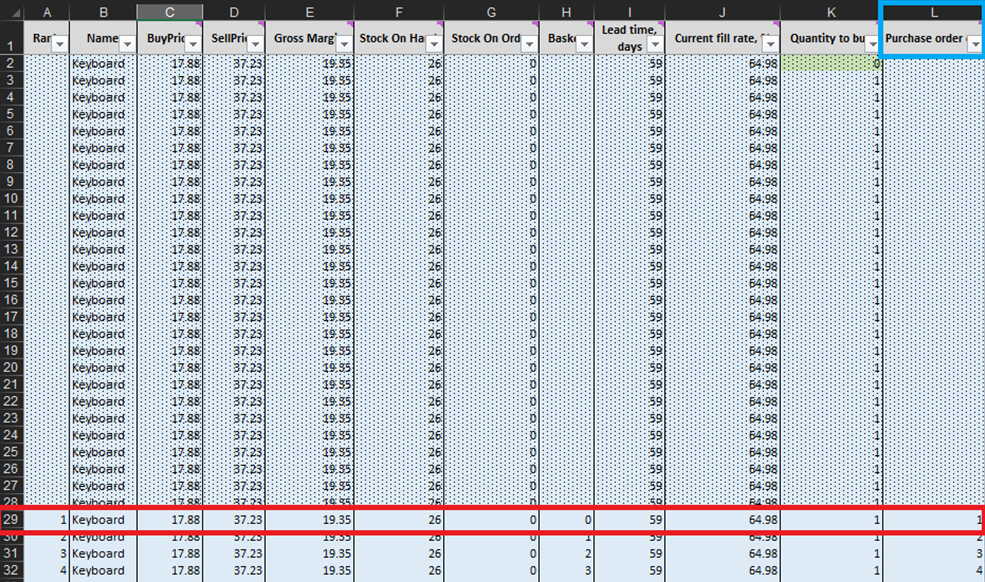
Рисунок 10. Вид изнутри листа Микро решения по закупкам. Строка 29, выделенная красным, – это начало нашего эксперимента (на примере клавиатур). Столбец заказа закупки выделен синим. Тот же принцип применяется к строкам 140 (для заказа ручек) и 240 (для заказа книжных шкафов).
После определения этих допустимых решений по пополнению запасов мы рассчитаем и ранжируем экономическую выгоду каждого возможного заказа. Обратите внимание, что мы не оцениваем экономическую выгоду заказа для единиц, которые в настоящее время являются либо текущими запасами, либо заказанными запасами (столбцы F и G на Рисунке 10). Поскольку эти единицы уже закуплены, теоретическая экономическая выгода была определена (и оценена) ранее. Например, если мы рассмотрим данные по клавиатурам на Рисунке 10, то в настоящее время в запасе находится 26 единиц. Таким образом, мы начнём расчёты со строки 29 и рассмотрим, стоит ли заказывать первую дополнительную единицу запасов (что увеличит уровень запасов с 26 до 27 единиц).
3.1 Оценка допустимых решений о закупке
Чтобы выбрать оптимальное количество закупки для каждого продукта, необходимо вычислить ожидаемую денежную отдачу на уровне единицы для каждого допустимого варианта количества для каждого продукта (с учётом неопределённого будущего, представленным вероятностным прогнозом). Это понятие ожидаемой стоимости, адаптированное к наиболее детальному уровню принятия решений в области запасов (decision-making).
На самом деле, при попытке рассчитать ожидаемую отдачу для каждого допустимого решения следует учитывать все виды экономических факторов7. Для целей данной демонстрации рассмотрим следующие факторы:
- Цена продажи: какую цену мы устанавливаем для потребителей за продукт.
- Стоимость хранения: сколько нам стоит хранение продукта.
- Цена закупки: сколько нам стоит приобрести продукт у поставщика/оптовика.
- Покрытие дефицита: подробно рассмотрено ниже, так как является менее известным, но всё же важным фактором8.
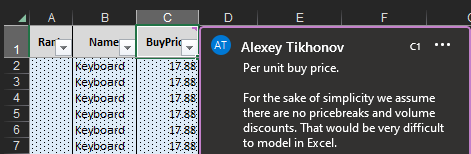
Рисунок 11. Пояснительная записка для цены закупки, которую можно увидеть, наведя курсор на заголовок столбца. Определение каждого столбца присутствует на каждом листе Excel документа.
Покрытие дефицита представляет собой финансовый стимул для удержания единицы продукта на складе, но не с явной целью его продажи. Этот экономический фактор используется для моделирования относительной важности продукта по сравнению с другими. Он стимулирует избежание дефицита для продуктов, которые могут восприниматься как менее важные из-за их прямого вклада в маржу, так как такие продукты могут существенно способствовать прибыли косвенным образом. Таким образом, он больше похож на фактор отдачи9. Хотя этот фактор является размытым, крайне важно определить все критические продукты (даже те, которые не являются прямыми драйверами маржи).
3.2 Расчёт балла для каждого допустимого решения
Общая экономическая выгода (или выгода от закупки) решения по пополнению запасов равна сумме всех экономических факторов, включая ожидаемую маржу, ожидаемую стоимость запасов и покрытие дефицита (подробно определено ниже). Стоимость хранения включена в эти расчёты как отрицательный фактор, действующий как противовес нашим решениям по пополнению запасов.
Ниже приведён анализ экономических последствий формул в каждом столбце, на примере строки 29 листа Микро решения по закупкам (см. Рисунок 12).

Рисунок 12. Разбивка факторов по ключевым столбцам, на примере строки 29 листа Микро решения по закупкам (лист Excel 2). Некоторые столбцы скрыты для удобства изображения.
Для вычисления ожидаемой выгоды для каждого решения нам необходимы следующие факторы:
Валовая маржа (столбец E) = Цена продажи – Цена закупки.
Вероятность продажи (столбец Q) = см. формулу на листе10.
Вероятность непродажи (без столбца) = 100% - Вероятность продажи
Ожидаемая маржа (столбец R) = Валовая маржа * Вероятность продажи/100.
Фактор агрессивности (столбец S) = варьируется от 0 до 1. Для этого инструмента выбран 0.8.
Покрытие дефицита (столбец T) = Цена продажи * Фактор агрессивности * Вероятность продажи
Стоимость хранения (столбец U)
Ожидаемая стоимость запасов (столбец V) = Стоимость хранения * Вероятность непродажи11.
Используя приведённые данные, выгода от закупки для каждого микро уровня решения по пополнению запасов (каждая единица каждого продукта) вычисляется следующим образом:
Выгода от закупки (столбец W) = Ожидаемая маржа + Покрытие дефицита + Ожидаемая стоимость запасов.
После получения оценки выгоды от закупки мы можем вычислить итоговый балл, который позже будет использован для ранжирования всех рассмотренных решений.
Балл (столбец Y) = Выгода от закупки / Инвестиции (столбец X)12.
Поскольку покрытие дефицита является размытым фактором, учитывающим как прямую, так и косвенную отдачу, выгода от закупки не является строгим отражением ожидаемой отдачи решения по пополнению запасов самостоятельно. Если необходимо рассчитать именно этот тип отдачи, следует исключить покрытие дефицита из данной формулы13.
4. Ранжирование допустимых решений по пополнению запасов
После вычисления баллов для каждого допустимого решения по закупке запасов (для каждого продукта) формируется список, который сортируется по убыванию (от наибольшего к наименьшему) в разделе Ранжированные решения по закупкам (см. Рисунок 13). Каждое допустимое решение сортируется по положительной ROI %. Порядковый рейтинг (1-е, 2-е, 3-е и т.д.) также присваивается каждому решению (см. столбец A на том же рисунке).
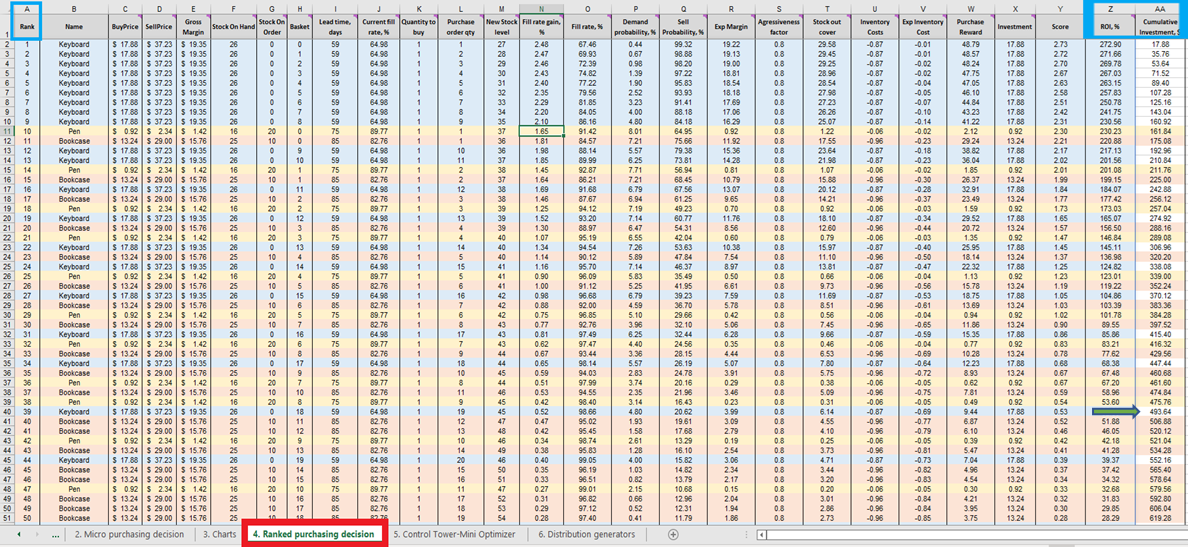
Рисунок 13. Раздел Ранжированные решения по закупкам выделен красным. Столбцы A, Z и AA выделены синим. Ячейка 40 (точка отсечения для бюджета $500 – настройка по умолчанию в таблице) указана зелёной стрелкой.
Ранжированные решения по закупкам содержат строки, окрашенные в разные цвета для каждого продукта (клавиатуры, ручки и книжные шкафы), что демонстрирует, как выбор добавить одну дополнительную единицу любого продукта взаимодействует с каждой другой дополнительной единицей каждого другого продукта. Каждое из этих решений по запасам коллективно влияет на ROI. Наконец, рассчитывается значение совокупных инвестиций (столбец AA, Рисунок 13). Это значение может служить индикатором того, где следует прекратить принятие решений о закупке с учётом бюджетных ограничений - хотя это всего лишь один из возможных критериев остановки14.
5. Определение критериев остановки
При выборе точки остановки (как в разделе Ранжированные решения по закупкам, так и в реальности) критерии будут варьироваться в зависимости от множества переменных. Например, у кого-то может быть скромный бюджет, и поэтому максимизация ROI вызывает трудности с учётом особенно узких маржей. Либо, возможно, существует общая цель по уровню обслуживания, которую необходимо сбалансировать с потребностью максимизировать прибыльные маржи.
Если углубиться, критерии остановки могут включать в себя стремление к максимальному ROI с вариабельными целевыми уровнями обслуживания для каждого продукта или категории. Таким образом, критерии остановки представляют собой стратегический выбор, который должен быть сделан после откровенного анализа общих бизнес-целей компании. Приоритетное пополнение запасов (PIR) в этом отношении удивительно гибко; критерии остановки для каждого цикла закупок могут быть настроены с использованием той же процедуры ранжирования.
Для наглядной визуализации возможных решений по пополнению запасов для каждого продукта в Диаграммах панели управления (лист 3, см. Рисунок 14) представлено три графика и диаграммы. Особый интерес представляет «Driving forces_product name» (на примере клавиатуры, см. Рисунок 14), который демонстрирует изменение ROI при различных количествах закупки на уровне единицы.
Как видно из диаграммы, существует точка, при которой увеличение количества закупок приведёт к отрицательному ROI. Это происходит потому, что, достигнув определённого уровня, нет смысла закупать больше единиц, поскольку наши ожидаемые маржи будут критически снижены за счёт увеличения ожидаемых затрат на запасы.
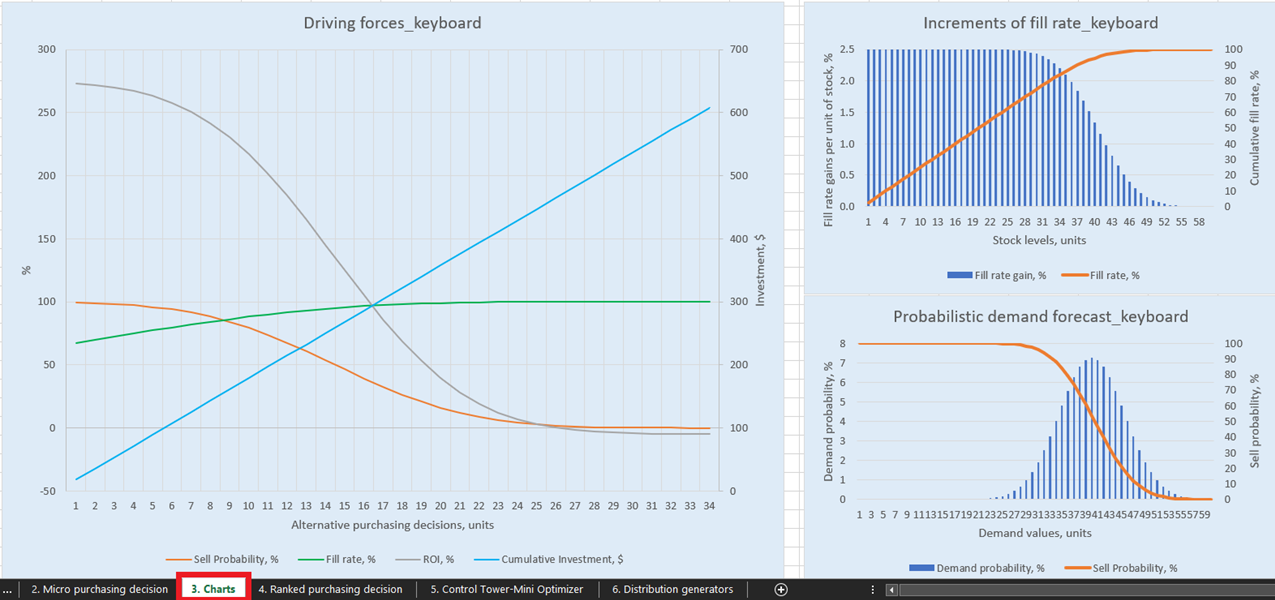
Рисунок 14. Вид «Driving forces_keyboard» в разделе Диаграммы, местоположение выделено красным.
После определения критериев остановки приоритетные решения по пополнению запасов объединяются по SKU, что, в свою очередь, обновляет значения Количество, Инвестиции и Ожидаемый уровень заполнения в Выходе – Рекомендация по закупкам для каждого SKU (см. Рисунок 15). Можно изменить ограничения бюджета ($0 до $1450), что, в свою очередь, обновит рекомендуемый список закупок. Для удобства в контрольной башне предусмотрены два дополнительных блока: Базовый сценарий – печатная версия и Изменения базового сценария. Первый является статичным и отображает настройки по умолчанию для демонстрации, разработанные Lokad; второй отображает разницу между внесёнными изменениями и настройками по умолчанию Lokad.
Список рекомендаций по закупкам в Контрольной башне представляет цель данной демонстрации (см. Рисунок 15).
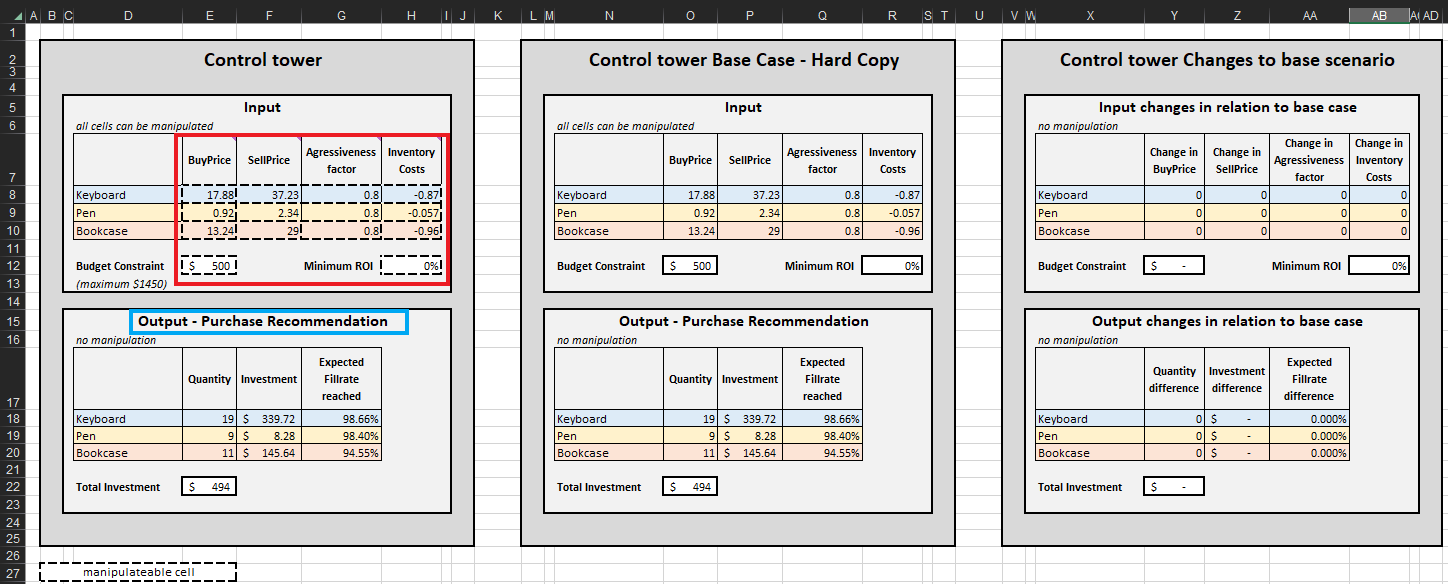
Рисунок 15. Вид _Контрольной башни-Мини Оптимизатора_ (лист 5). Изменяемые ячейки выделены красным. «Рекомендация по закупкам» выделена синим и представляет цель приоритетного подхода к пополнению запасов.
6. Заключение
Традиционные прогнозы временных рядов просто не способны уловить необходимый уровень детализации, позволяющий принимать решения о пополнении запасов, которые учитывают будущую неопределенность и все ограничения и драйверы. Это связано с тем, что в них отсутствует явное измерение неопределенности, представленное значениями вероятности для ожидаемых будущих результатов. Поскольку традиционный временной ряд фактически «слеп» к такого рода данным, классический метод, такой как страховой запас, сводится к догадкам; если его недостаточно – то упускаются прибыльные продажи с положительным ожидаемым ROI, а если его слишком много – ROI снижается за счет хранения единиц, которые (как показано в таблице) имеют отрицательный ожидаемый ROI.
Приоритетное пополнение запасов с использованием вероятностных прогнозов является нашим решением этой проблемы. Такой подход рассматривает варианты пополнения запасов в комбинации, а не по отдельности. Таким образом, ожидаемое финансовое вознаграждение от наших решений по пополнению запасов может быть полностью количественно оценено и выявлено. Основой такого подхода является принятие неопределенности и использование входных данных вероятностного прогноза. В свою очередь, это позволяет лучше понять, какие уровни обслуживания (на каждую SKU) приносят значимые финансовые результаты, а не устанавливать произвольные цели.
Подход PIR, показанный в этом документе, был создан с использованием синтетических данных и узких параметров. Эти решения были приняты для адаптации обычного инструмента (Excel) к нестандартной задаче (PIR). Среди прочих необходимых уступок, количество SKU и единиц было ограничено (до 3 и 100 соответственно) для сокращения времени обработки, поскольку данные для всего каталога (не говоря уже о данных нескольких магазинов) оказались бы слишком объемными для обработки. Кроме того, никаких ограничений цепочки поставок не было добавлено. Важно отметить, что Excel не предназначен для обработки случайных величин — ключевого шага в построении вероятностных прогнозов и политики PIR. Эти ограничения не применимы к промышленному решению класса PIR.
Практики в области цепочки поставок, чьи бизнесы переросли возможности Excel, приглашаются написать на contact@lokad.com для организации демонстрации промышленного решения класса PIR.
7. Обзор таблицы
7.1 Инструкция
Этот лист служит посадочной страницей для пользователя. Здесь имеется ссылка на онлайн-учебник (тот, который вы читаете сейчас).
7.2 Микро закупочные решения
Это второй лист, посвященный детальному финансовому анализу всех возможных вариантов пополнения запасов. Обратите внимание, что никакая ручная обработка данных здесь не производится. Этот лист отображает лишь результаты вычислений, основанных на данных с листов Control Tower и Distribution generators.
Ключевые особенности:
- Строки с условным форматированием представляют собой «принятые решения» и не могут быть изменены. Мы рекомендуем использовать настольное приложение, так как браузерная версия Excel иногда ненадежна в плане форматирования.
- При наведении на заголовок столбца будет показано полезное определение/примечание.
7.3 Диаграммы
Это третий лист, предназначенный для визуализации основных факторов, влияющих на решения по пополнению запасов. Обратите внимание, что никакая ручная обработка данных здесь не производится. Этот лист создан, чтобы помочь специалисту визуализировать (и, таким образом, лучше понять) внутреннюю работу процесса PIR.
Ключевые особенности:
- Три графика на каждую SKU (клавиатура, ручка и книжный шкаф).
- Диаграмма «движущих сил» визуализирует основные движущие силы для каждого решения на уровне единицы (для каждой SKU). Именно поэтому ось x содержит только те единицы SKU, которые еще не заказаны.
- Еще две диаграммы («приращения уровня заполненности» и «вероятностный прогноз спроса») отображают все единицы запасов – те, что есть на складе, и те, которые можно заказать.
7.4 Ранжированные решения по закупкам
Это четвертый лист, предназначенный для перечисления всех возможных решений по пополнению запасов, отсортированных по ROI/оценке в порядке убывания. Этот список автоматически формируется на основе данных с листа 2 (Микро закупочные решения). Возможные решения представлены относительно друг друга (см. «Ключевые особенности» ниже). Обратите внимание, что никакая ручная обработка данных здесь не производится. В зависимости от изменений, внесенных во входные данные на листах 5 и 6, этот список будет меняться.
Ключевые особенности:
- Возможные решения по пополнению запасов ранжируются в порядке убывания (от наивысшего к низшему) по ROI/оценке.
- Кумулятивные инвестиции рассчитываются для отсортированных решений (см. столбец AA на листе 4).
- При наведении на заголовок столбца будет показано полезное определение/примечание.
7.5 Контрольная башня - мини оптимизатор
Это пятый лист, который суммирует предположения модели (входные данные) и рекомендованные решения (выходные данные). Данные в изменяемых ячейках можно изменить для корректировки предположений модели и, соответственно, ее результатов.
Ключевые особенности:
- Три блока для помощи при демонстрации: «Control tower» для ручного изменения входных данных; «Base Case – Hard copy» для отображения настроек по умолчанию; и «Changes to base scenario» для показа разницы между обновленными и стандартными настройками (см. лист 5).
- Четвертый блок («Model Assumptions»), расположенный под «Control tower», предназначен для изменения первоначальных предположений о запасах (см. лист 5).
- Изменять можно только данные в изменяемых ячейках.
7.6 Генераторы распределения
Это шестой лист, предназначенный для генерации вероятностных прогнозов спроса. Параметры в изменяемых ячейках можно корректировать, что приведет к обновлению распределений и отображению новых значений вероятностного спроса.
Ключевые особенности:
- Один график распределения на каждую SKU.
- У каждой SKU своя схема распределения (обоснование приведено в разделе 2.1).
- Слева от ряда графиков распределения располагается таблица, предназначенная для изменения параметров распределений.
- Изменять можно только параметры в изменяемых ячейках.
- При наведении на соответствующие заголовки столбцов таблицы будет показано полезное определение/примечание.
Примечания
-
Рассмотрим молоко и шоколад. Первое является продуктом с низкой маржой, но считается основным товаром, в то время как второе — дополнительным и обладает более высокой прибылью. Люди, как правило, покупают основные и дополнительные товары вместе, но штраф за отсутствие молока отличается от штрафа за отсутствие шоколада. Клиент может заменить один дополнительный товар (печенье) на другой (шоколад) при отсутствии товара, но если он не может приобрести основной (молоко), он может вообще уйти из магазина. Именно поэтому покрытие дефицита будет выше для молока, чем для шоколада, независимо от валовой прибыли. С нашей точки зрения, покрытие дефицита является вознаграждением, а не наказанием, поскольку оно предназначено для увеличения продаж. ↩︎
-
Трех продуктов достаточно, чтобы проиллюстрировать концепцию, а также сохранить документ кратким и понятным. ↩︎
-
Уровни запасов становятся вероятностными, когда мы вычитаем вероятностный спрос из дискретных значений запасов (дискретное значение минус распределение вероятностей дает новое распределение вероятностей). Все это делает объяснение через Excel слишком сложным, так как он не предназначен для выполнения вычислений со случайными величинами (например, с распределениями вероятности спроса). ↩︎
-
Эти уступки необходимы для демонстрации общего принципа вероятностного подхода. На практике отложенные заказы используются не всегда, а сроки поставки являются вероятностными и могут меняться. ↩︎
-
В целях простоты мы не применяли никаких ограничений цепочки поставок. ↩︎
-
Как упоминалось ранее, нет необходимости редактировать данные на листе «Микро закупочные решения». Все изменения данных проводятся через листы 5 и 6. ↩︎
-
В этом листе Excel экономические показатели выражены в долларах, хотя валюта не имеет значения. ↩︎
-
Приведенный выше список экономических драйверов не является исчерпывающим, и реальные сценарии пополнения запасов (и цепочки поставок) почти наверняка будут содержать больше факторов. Это особенно верно при производстве товаров и наличии ограничений, связанных со скоропортящимися продуктами. ↩︎
-
Этот драйвер менее определен в контексте B2C, чем в B2B. Для последних часто существуют явные штрафы за отсутствие товара, например, контрактные санкции; для первых трудно финансово оценить негативное влияние отсутствия товара. Как правило, он будет высоким для продуктов, которые оказывают непропорционально негативное влияние на привлекательность бизнеса (независимо от прямого вклада SKU в маржу). Молоко, как уже упоминалось, не является драйвером маржи для супермаркетов, но его стратегическое расположение (обычно в задней части магазина) заставляет покупателей проходить мимо ряда других товаров (почти все с более высокой маржой). Если супермаркет столкнется с отсутствием этого основного продукта (товара, который люди покупают регулярно и в наборах), это может побудить покупателей уйти, совершить покупки в другом месте и, возможно, не вернуться (если такие случаи происходят регулярно). ↩︎
-
Вероятность продажи выводится из распределений вероятностей, сгенерированных на листе «Distribution generators» (лист 6). ↩︎
-
Текущие затраты связаны с тем, что если товар не продается, его приходится хранить. ↩︎
-
В данном случае инвестиция равна цене покупки, но только потому, что наши решения по закупкам не ограничены минимальными объемами заказа или множителями партий. ↩︎
-
Проще всего установить коэффициент агрессивности (столбец S на Рисунке 12) равным нулю, что компания может сделать, если решит, что событие отсутствия товара не имеет негативных последствий. Небольшой бесплатный совет: оно определенно оказывает негативное влияние. ↩︎
-
Например, наш бюджет по умолчанию составляет 500 долларов, поэтому мы завершали бы принятие решений по закупкам на ячейке 40 (см. Рисунок 13), так как ячейка 41 имеет значение 506,88 долларов и превышает наш бюджет. Затем мы агрегировали бы показатели по каждому продукту, что составляло бы наш список закупок (см. «Purchase recommendation» в разделе Control Tower, согласно Рисунку 2). Как уже упоминалось, можно изменить установленный бюджет в 500 долларов (см. Рисунок 2 для инструкций) на любое значение от 0 до 1450 долларов. Это продемонстрирует, как список закупок меняется при различных бюджетных ограничениях. Независимо от финансовых ограничений, ранжированные решения по закупкам определят наилучшую возможную комбинацию решений по запасам с точки зрения ROI для всех строк от ранга 1 до точки завершения. ↩︎