供給チェーンのためのプログラミングパラダイム(講義 1.4 概要)
供給チェーンの問題は手強いものであり、適切なプログラミングツールなしにこれらに対処しようとすること―特に大企業の文脈では―は必ず高額な学習経験となる。物理的かつ抽象的な複雑さが散在する供給チェーンを効果的に最適化するには、現代的で俊敏かつ革新的なプログラミングパラダイムの一式が必要である。これらのパラダイムは、供給チェーン固有の膨大かつ多様な問題の特定、検討、解決に不可欠である。
講義を視聴する

静的解析
コンピュータプログラマーでなくともそのように考えることは可能であり、供給チェーン問題の適切な解析は単なるプログラミングツールではなく、プログラミング的思考で取り組むのが最善である。従来のソフトウェアソリューション(例:ERPなど)は、問題が実行時ではなくコンパイル時に対処されるように設計されている1.
これがリアクティブな解決策とプロアクティブな解決策の違いである。この区別は極めて重要で、リアクティブな解決策は財政面や帯域幅の面で、プロアクティブなものよりもはるかに高コストになる傾向がある。これら大部分が回避可能なコストこそが、プログラミング的思考が排除しようとするものであり、静的解析はそのフレームワークの表れである。
静的解析とは、プログラム(この場合は最適化)を実行せずに検査することで、生産に影響を与える前に潜在的な問題を特定する手法である。Lokadは独自のドメイン固有言語(DSL)であるEnvisionを用いて静的解析に取り組む。これにより、プログラミング言語の設計レベルでのミスを迅速かつ便利に特定し、修正することが可能となる。
ある企業が倉庫の建設を進めていると考えてみよう。まず倉庫を建設してからそのレイアウトを考えるのではなく、通路、ラック、荷役ドックの戦略的配置を事前に検討し、建設前に潜在的なボトルネックを特定する。これにより、将来の倉庫内における最適な設計―すなわち物流の流れ―が可能となる。このような慎重な設計図作成は、LokadがEnvisionを通じて行う静的解析に類似している。
ここで説明する静的解析は、最適化の根底にあるプログラミングをモデル化し、実装前にレシピ内の潜在的な有害な挙動を特定する。これらの有害な傾向には、必要以上の在庫が誤って発注されるようなバグが含まれる可能性がある。結果として、そのようなバグは大混乱を引き起こす前にコードから除去される。
配列プログラミング
供給チェーンの最適化では、厳格な時間管理が不可欠である。例えば、小売チェーンでは、データを統合し最適化した上で、60分以内に倉庫管理システムへ送らなければならない。計算に時間がかかりすぎると、供給チェーン全体の運用が危うくなる。配列プログラミングは、特定のプログラミングエラーを排除し、計算時間を保証することで、この問題に対処し、供給チェーン実務者にデータ処理の予測可能な時間枠を提供する。
別名データフレームプログラミングとも呼ばれるこの手法では、個々のデータではなくデータ配列全体に直接操作を行うことができる。Lokadは自社のDSLであるEnvisionを活用してこれを実現している。配列プログラミングは、テーブル内の個々のエントリではなく、データの全列に対して操作を行うことで、データ操作や解析を簡素化できる。これにより解析の効率が飛躍的に向上し、プログラミングにおけるバグの発生率も低減される。
例えば、倉庫管理者が2つのリストを持っているとする。リストAは現在の在庫レベルを示し、リストBはリストAに含まれる製品の入荷分である。各製品ごとに一つずつ手作業で入荷分(リストB)を現在の在庫レベル(リストA)に加算する代わりに、両方のリストを同時に処理するより効率的な方法を用いることで、一度にすべての製品の在庫レベルを更新できる。これにより、時間と労力が節約され、本質的に配列プログラミングが目指すところである2.
実際、配列プログラミングは、供給チェーンの最適化に関与する膨大なデータの計算を並列化および分散処理することを容易にする。複数のマシンに計算を分散させることで、コストを削減し実行時間を短縮することが可能となる。
ハードウェアの融合性
供給チェーン最適化の主要なボトルネックの1つは、サプライチェーン-サイエンティストの人数の限られていることである。これらの科学者は、顧客の戦略や競合他社の敵対的な策略を考慮に入れた数値レシピを作成し、実行可能な洞察を生み出す責任を担っている。
これらの専門家の確保が困難なだけでなく、確保できたとしても、彼らはタスクの迅速な実行から隔てるいくつかのハードウェア上の障害を乗り越えなければならない。ハードウェアの融合性、すなわちシステム内の各コンポーネントが調和し共に機能する能力は、これらの障害を取り除くために極めて重要である。ここで考慮される3つの基本的な計算資源がある:
- Compute: CPUまたはGPUによって提供されるコンピュータの処理能力。
- Memory: RAMまたはROMによって提供される、コンピュータのデータ保存容量。
- Bandwidth: コンピュータの各部分間、またはコンピュータネットワーク全体でデータ(情報)が転送される最大速度。
大量のデータセットの処理は一般的に時間がかかるため、エンジニアがジョブの実行を待つ間、生産性が低下する。供給チェーン最適化では、定型の中間計算ステップを表すコードの断片をソリッドステートドライブ(SSD)に保存することができる。このシンプルな手法により、サプライチェーン・サイエンティストは、わずかな変更を加えた類似のスクリプトをはるかに迅速に実行することができ、生産性が大幅に向上する。
上記の例では、低コストなメモリハックを活用して計算負荷を軽減している。システムは、処理中のスクリプトが以前のものとほぼ同一であることに着目し、そのため計算が数十分ではなく数秒で実行できる。
このようなハードウェアの融合性により、企業は投資した資金から最大の価値を引き出すことができる。
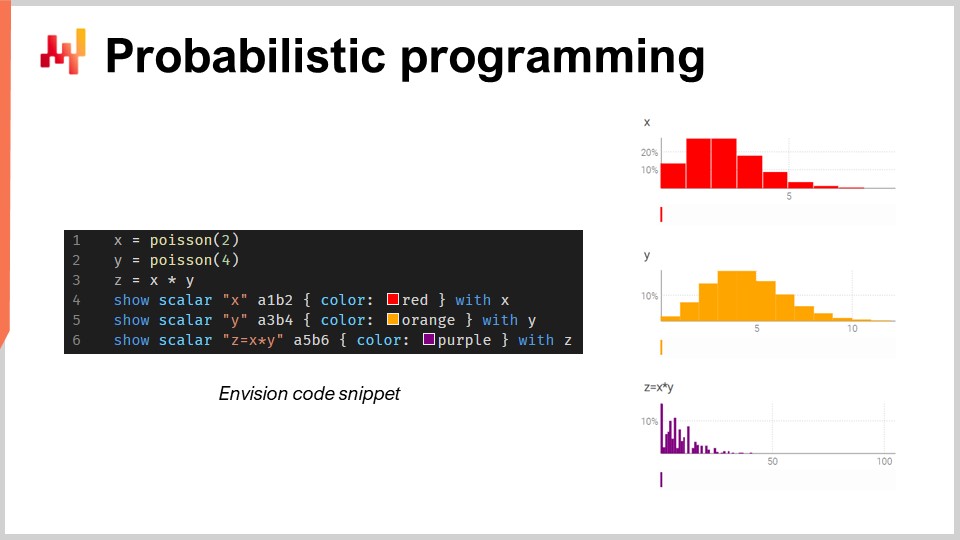
確率的プログラミング
将来の結果は無限にあり得るが、その全てが同じ確率で発生するわけではない。この排除不可能な不確実性を考慮すると、プログラミングツールは確率的予測のパラダイムを採用する必要がある。Excelは歴史的に多くの供給チェーンの基盤であったが、この種の予測は乱数変数の代数学を処理する能力を必要とするため、確率的予測を用いて大規模に展開することはできない3.
要するに、Excelは主に静的な全数などの確定的なデータを対象に設計されている。多少の確率関数を実行するように改変することは可能だが、複雑な乱数変数の操作を必要とする確率的需要予測に対処するための高度な機能、柔軟性、および表現力に欠けている。むしろ、Envisionのような確率的プログラミング言語の方が、供給チェーンにおける不確実性の表現と処理に適している。
例えば、自動車のアフターマーケット店舗がブレーキパッドを販売しているとする。この仮定のシナリオでは、顧客は一度に2個または4個単位でブレーキパッドを購入する必要があり、店舗は需要予測の際にこの不確実性を考慮しなければならない。
店舗がスプレッドシートの海ではなく、確率的プログラミング言語を利用できれば、一般的なプログラミング言語にはない乱数変数の代数学を用いて、総消費量をはるかに正確に推定することができる。
微分可能プログラミング
供給チェーン最適化の文脈において、微分可能プログラミングは、数値レシピが与えられたデータに基づいて学習し適応することを可能にする。微分可能プログラミングは確率的勾配降下法と組み合わせることで、サプライチェーン・サイエンティストが供給チェーン内の複雑なパターンや関係性を発見することを可能にする。各反復ごとにパラメータが学習され、このプロセスは何千回も繰り返される。これは、現在の予測モデルと過去のデータとの乖離を最小限に抑えるために行われる4.
カニバリゼーションと代替―単一カタログ内で―は、この文脈で解明すべき2つのモデル問題である。どちらの場合も、複数の製品が同じ顧客を争うため、予測の複雑性が一層増す。これらの影響は、従来の時系列予測では、主にトレンド、季節性、および単一製品に対するノイズのみが考慮され、相互作用の可能性が考慮されないため、十分に捉えられない。
微分可能プログラミングと確率的勾配降下法を活用することで、顧客と製品を結ぶ取引の歴史的データを分析し、これらの問題に対処することができる。Envisionは、十分な歴史的記録―すなわち取引、日付、製品、顧客、購入数量―を含む単純なフラットファイルを読み取ることで、顧客と購買間の関連性分析(アフィニティ分析と呼ばれる)を実行する能力を持つ5.
僅か数行のユニークなコードを用いるだけで、Envisionは顧客と製品間の親和性を特定することができ、これによりサプライチェーン・サイエンティストは、対象となる推奨事項を提供する数値レシピをさらに最適化できるようになる6.
コードとデータのバージョン管理
長期的な最適化の実現性において見落とされがちな要素は、数値レシピ―すなわち、構成する各コード断片とデータの微細な部分すべてが、ソース追跡され再現可能であることを保証することである7. このバージョン管理機能がなければ、厄介な例外(コンピュータ界でのハイゼンバグ)が必然的に発生した際に、そのレシピを逆解析する能力は大きく損なわれる。
ハイゼンバグとは、最適化計算に問題を引き起こす厄介な例外でありながら、プロセスを再実行すると消えてしまうものである。これにより、修正が非常に困難になり、一部の取り組みが失敗し、供給チェーンがExcelスプレッドシートに戻る結果となる。ハイゼンバグを避けるためには、最適化の論理とデータが完全に再現可能であることが必要である。これは、プロセスで使用されるすべてのコードとデータをバージョン管理し、環境が過去の任意の時点と全く同じ条件で再現できるようにすることを要求する。
セキュアプログラミング
不良なハイゼンバグを超えて、供給チェーンのデジタル化の進展は、サイバー攻撃やランサムウェアなどのデジタル脅威に対する脆弱性を伴う。この点で、混沌を引き起こす主要な2つの要因―使用するプログラム可能なシステムと、そのシステムを使用することを許可する人々―が存在する。後者に関しては、偶発的な無能(ましてや意図的な悪意による事件)を考慮するのは非常に困難であり、前者については、これらの落とし穴を回避するために行う設計レベルでの意図的な選択が極めて重要である。
貴重な資源を費やしてサイバーセキュリティチームを増強する(例えば、火消し作業のようなリアクティブな対応を前提とする)代わりに、プログラミングシステムの設計段階で慎重な判断を下すことで、下流の煩わしい問題の全クラスを排除できる。余分な機能―例えば、Lokadの場合のSQLデータベース―を除去することで、SQLインジェクション攻撃のような予測可能な大惨事を防ぐことができる。同様に、Lokadが採用しているような追加専用の永続化レイヤを選択することで、データを(友か敵かを問わず)削除することが非常に困難になる8.
ExcelやPythonにはそれぞれの長所があるが、これらの講義で論じられるようなスケーラブルな供給チェーン最適化に必要な、すべてのコードとデータを保護するためのプログラミングセキュリティが欠如している。
注意
-
コンパイル時とは、プログラムのコードが実行される前に機械語に変換される段階を指す。実行時とは、プログラムが実際にコンピュータによって実行される段階を指す。 ↩︎
-
これはプロセスのおおまかな近似である。実際はもっと複雑だが、それはコンピュータ専門家の領域である。現時点では、配列プログラミングがはるかに効率的(コスト効率も高い)な計算プロセスをもたらし、その恩恵は供給チェーンの文脈で豊富であるという点が重要である。 ↩︎
-
簡単に言えば、これはサイコロを振る結果(あるいは大規模な供給チェーンネットワークにおける何十万回ものサイコロ振り)のような、ランダムな値の操作と組み合わせを指す。基本的な加算、減算、乗算から、分散、共分散、期待値の計算といった、はるかに複雑な関数に及ぶ。 ↩︎
-
実際のレシピを完璧に近づける試みをしてみてください。参照する基本のスキーマは存在するかもしれませんが、材料と調理法の完璧なバランスを獲得するのは難解です。実際、レシピには味だけではなく、食感や見た目に関する考慮事項もあります。完璧なレシピの反復を見つけるために、細かい調整を行い、その結果を記録します。ありとあらゆる調味料や調理器具を試すのではなく、各反復で得られるフィードバックに基づいて賢明な調整(例:塩分を少し多めまたは少なめに加える)を行います。反復するたびに最適な割合についての理解が深まり、レシピは進化していきます。根底にあるのは、まさに供給連鎖最適化における数値レシピに対して微分可能プログラミングと確率的勾配降下法が行うプロセスなのです。数学的な詳細については講義を確認してください。 ↩︎
-
既にカタログにある2つの製品間に強い親和性が認められる場合、それらは補完的、つまりしばしば一緒に購入されることを意味するかもしれません。顧客が非常に類似した2つの製品の間を切り替えることが確認された場合、代替の可能性を示唆している可能性があります。しかし、新製品が既存製品と強い親和性を示し、その結果として既存製品の売上が減少する場合、カニバリゼーションが起こっている可能性があります。 ↩︎
-
これらは関与する数学的操作の単純化された説明であることは言うまでもありません。とはいえ、講義で説明されている通り、その数学的操作は非常に難解なものではありません。 ↩︎
-
一般的なバージョン管理システムにはGitやSVNなどがあります。これらは複数の人が同じコード(または任意のコンテンツ)に同時に取り組み、変更をマージ(または拒否)することを可能にします。 ↩︎
-
追加専用の永続性レイヤーとは、既存のデータを変更または削除することなく、新たな情報をデータベースに追加するデータ保存戦略を指します。Lokadの追加専用セキュリティ設計については、その包括的なセキュリティFAQで取り上げられています。 ↩︎